

6月17日,智谱AI宣布正式上线并开源新一代旗舰模型GLM-5.2。该模型专为长程任务能力打造,核心特色包括1M无损上下文、强化Coding能力、Day 0适配国产算力平台,并采用MIT开源协议。
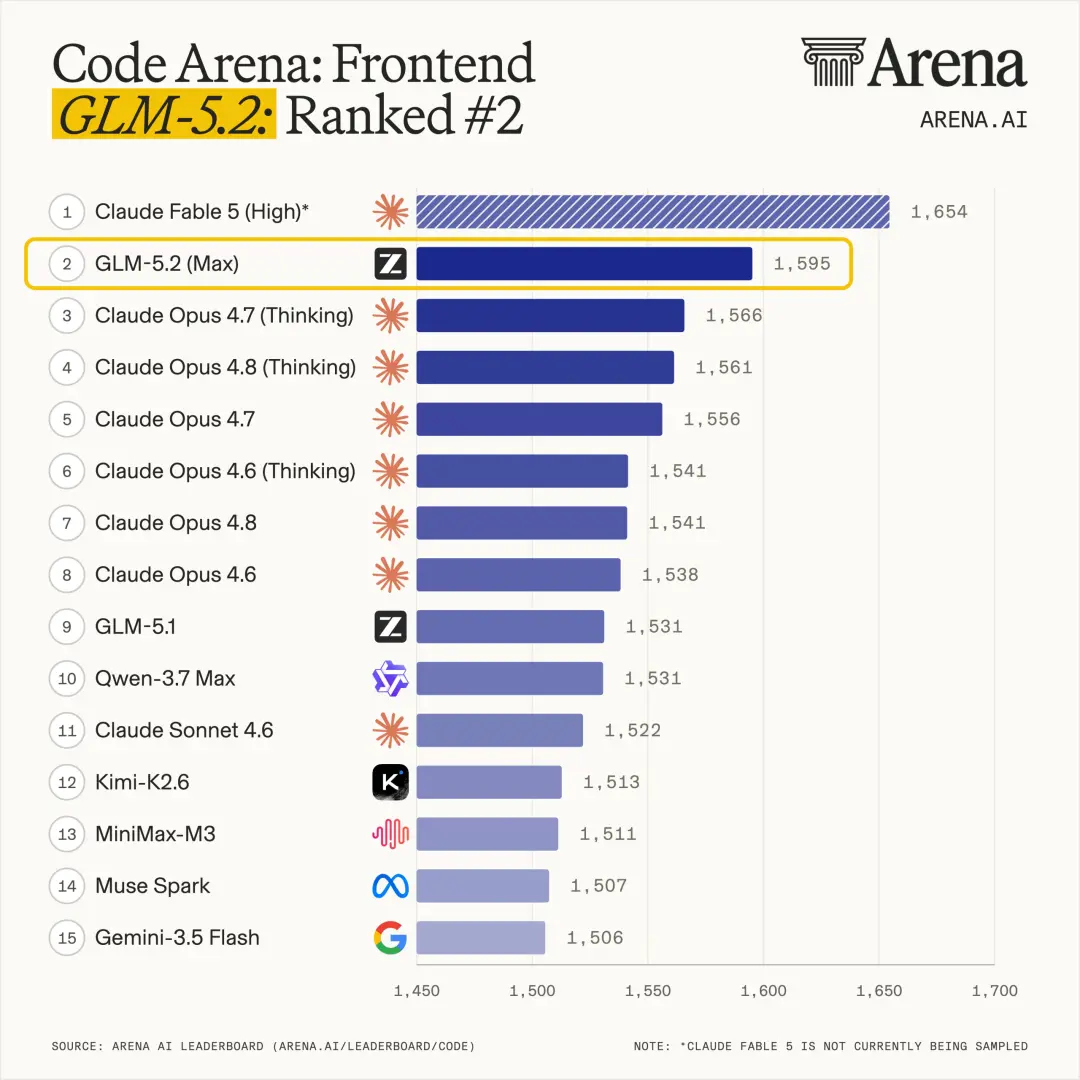
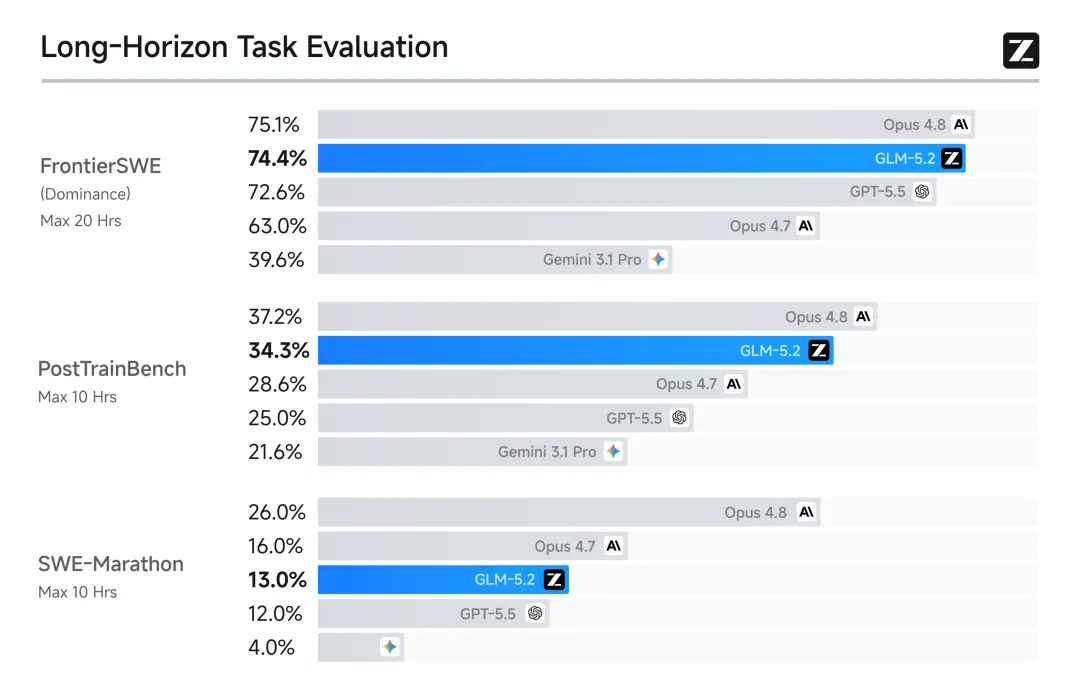
据智谱官方介绍,在全球百万用户参与盲测的前端开发评估系统Code Arena上,GLM-5.2取得全球可用模型第一的表现。在FrontierSWE、Terminal-Bench等多个权威评测中,GLM-5.2与海外头部模型Claude Opus 4.8的差距缩小至1%至4%,是排名最高的开源模型。其中,FrontierSWE测试中GLM-5.2仅比Opus 4.8低1%,超过GPT-5.5;Terminal-Bench 2.1评测中得分81.0,较前代GLM-5.1的63.5大幅提升17.5个百分点。
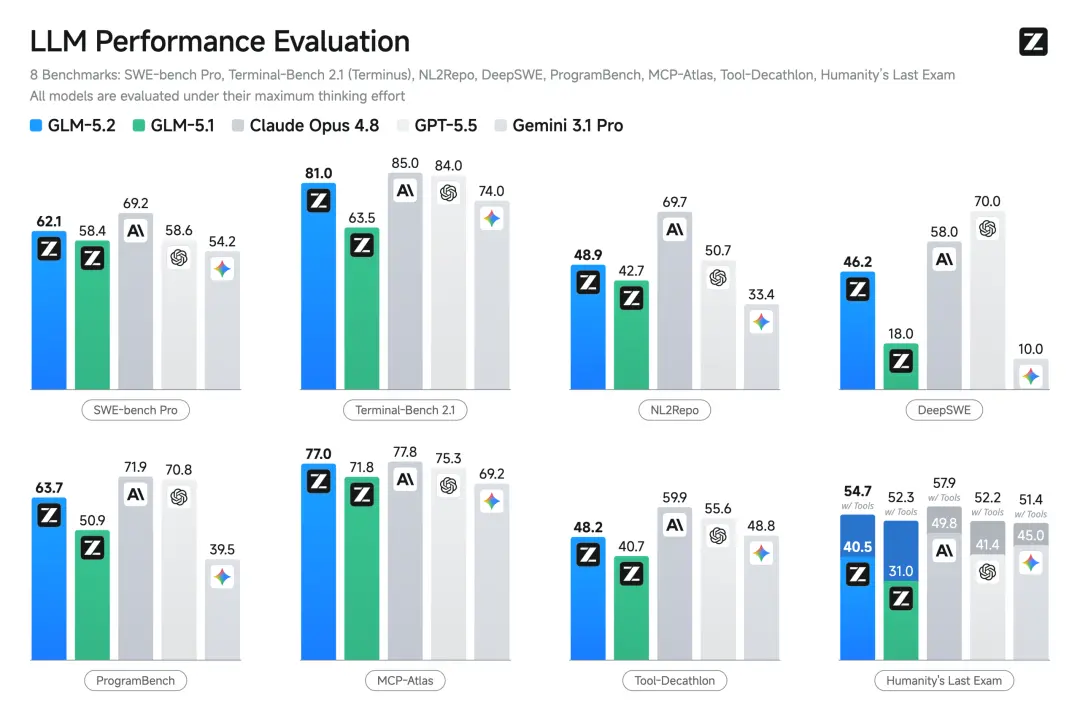
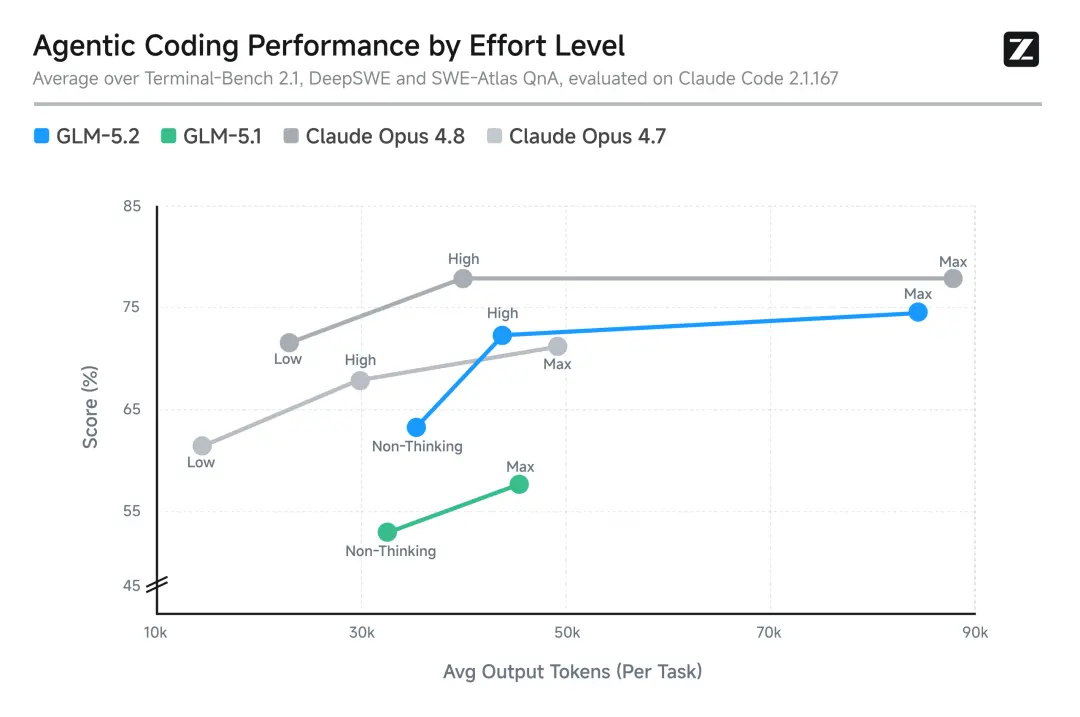
GLM-5.2实现了真正可用的1M上下文窗口,可在一个长程任务中完整承载大型软件工程项目。在实际测试中,模型一次性完成了覆盖Web、移动端与小程序的完整应用开发交付,累计处理88万tokens,几乎用满1M窗口。在SWE-bench Pro评测中,GLM-5.2得分62.1。
模型已率先向GLM Coding Plan全量用户开放。线上推理在Day 0完成与华为昇腾、平头哥、摩尔线程、寒武纪、昆仑芯、沐曦、海光、壁仞等国产算力平台的适配。GLM-5.2权重已上线Hugging Face与ModelScope,以最宽松的MIT协议开源,可自由下载、部署与商用。API同步上线BigModel开放平台与Z.ai。