

在今年 I/O 开发者大会前夕的 Android 专场活动上,Google再度将重心放在自家通用大模型 Gemini 上,宣布一系列围绕“帮你操控手机”的新功能,这些功能将出现在 Chrome 浏览器、系统自动填表以及更多应用场景中。
Google同时推出了一个全新的概念名称——“Gemini Intelligence”。据Google Android 体验总监 Ben Greenwood 介绍,这一名称代表“在最先进的Android设备上释放 Gemini 的最佳能力”,本质上是对现有与新功能的一次打包整合,且主要面向 Galaxy S26 等高端旗舰机型,形成类似“高级Android体验”的功能集合。
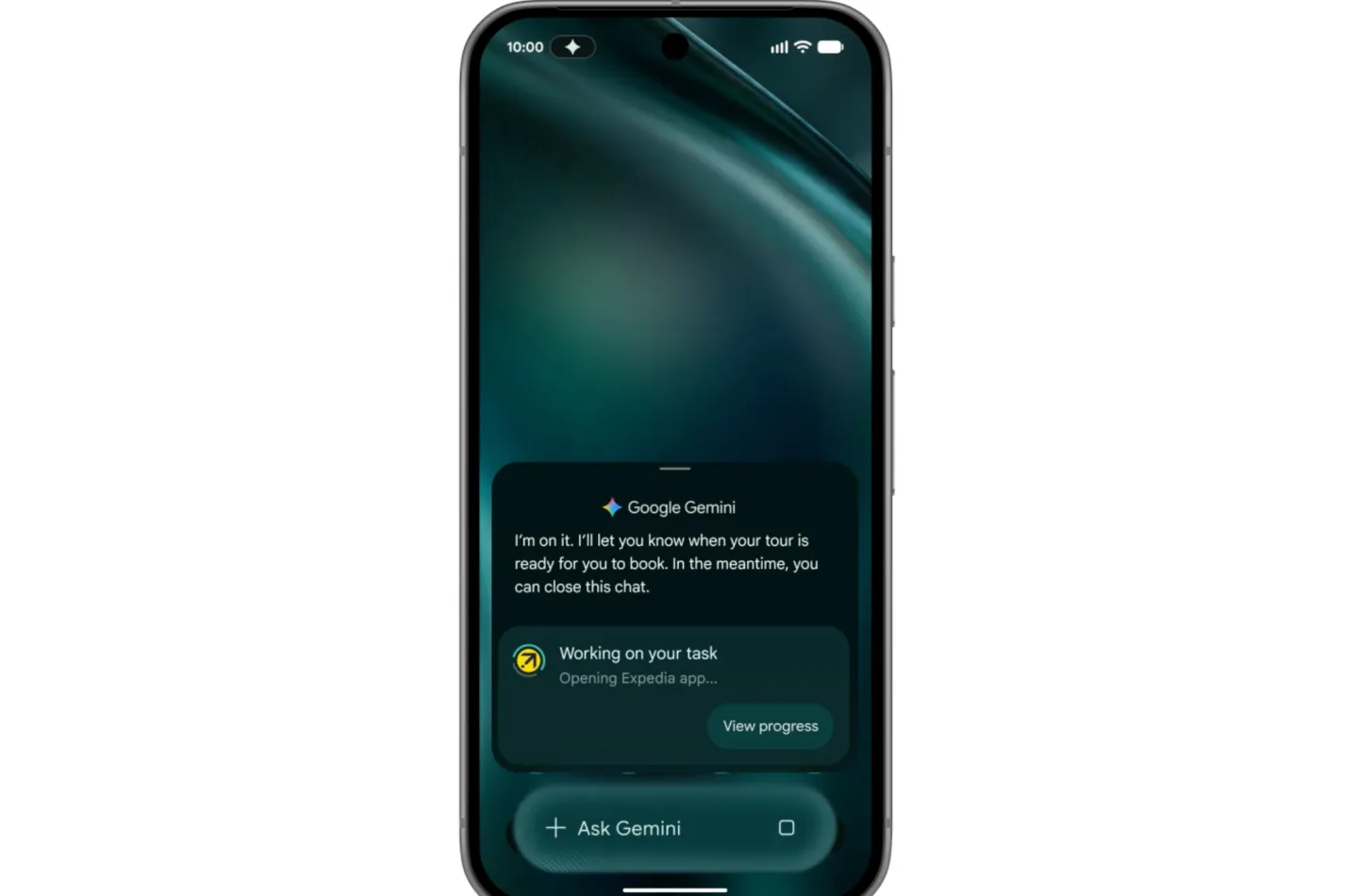
位于这一集合核心的,是此前已经在部分 Pixel 和三星 Galaxy 新机上测试的任务自动化功能。该功能允许 Gemini 直接在手机上代为操作特定应用,之前主要支持叫车与外卖等少数 App,如今Google宣布将“很快”开放到更广泛的应用生态中。 此外,任务自动化也将从仅支持语音和文本指令,升级为多模态输入,用户可以通过截图或照片来触发操作,例如把笔记应用里的一张购物清单截图交给 Gemini,由它在电商或买菜平台中自动添加购物车——前提是设备本身支持 Gemini Intelligence。
在 Gemini Intelligence 旗下,Google还首次公布一项名为“Create My Widget(创建我的组件)”的新功能,被官方视作迈向“生成式界面(generative UI)”的第一步。用户只需用自然语言描述自己想要的小组件功能,Gemini 便能自动生成对应的桌面组件。 Google给出的示例包括:为骑行爱好者定制一块突出显示风速和降水概率的天气组件,或是每周自动推荐“三个高蛋白备餐菜谱”的食谱组件。生成后,这些组件不仅能出现在手机桌面,还会同步扩展到 Wear OS 智能手表上,形成跨设备的统一体验。
从交互理念上看,Google希望用户把组件视作“可以随手用 AI 写在桌面上的迷你应用”,从而推动界面形态向即时生成、按需变化的方向演进。业界也由此关注,Google是否会在 I/O 大会上进一步阐释“生成式 UI”的长期路线:是让界面真正按场景即刻重构,还是更多停留在组件层面的个性化尝试。
除系统层功能外,Google还将 Gemini 的部分桌面端能力搬到了 Android 版 Chrome 浏览器中。未来用户将在 Chrome 内看到独立的 Gemini 按钮,可以直接把当前网页内容分享给 Gemini,并在浏览器内部就页面信息提问或生成摘要。 对于订阅了Google AI Pro 或 Ultra 计划的用户,Chrome 还会提供“自动浏览(auto browse)”辅助完成任务,例如自动帮你在网站间跳转、填信息并完成预约等。这一功能预计会在 6 月下旬开始逐步推送。
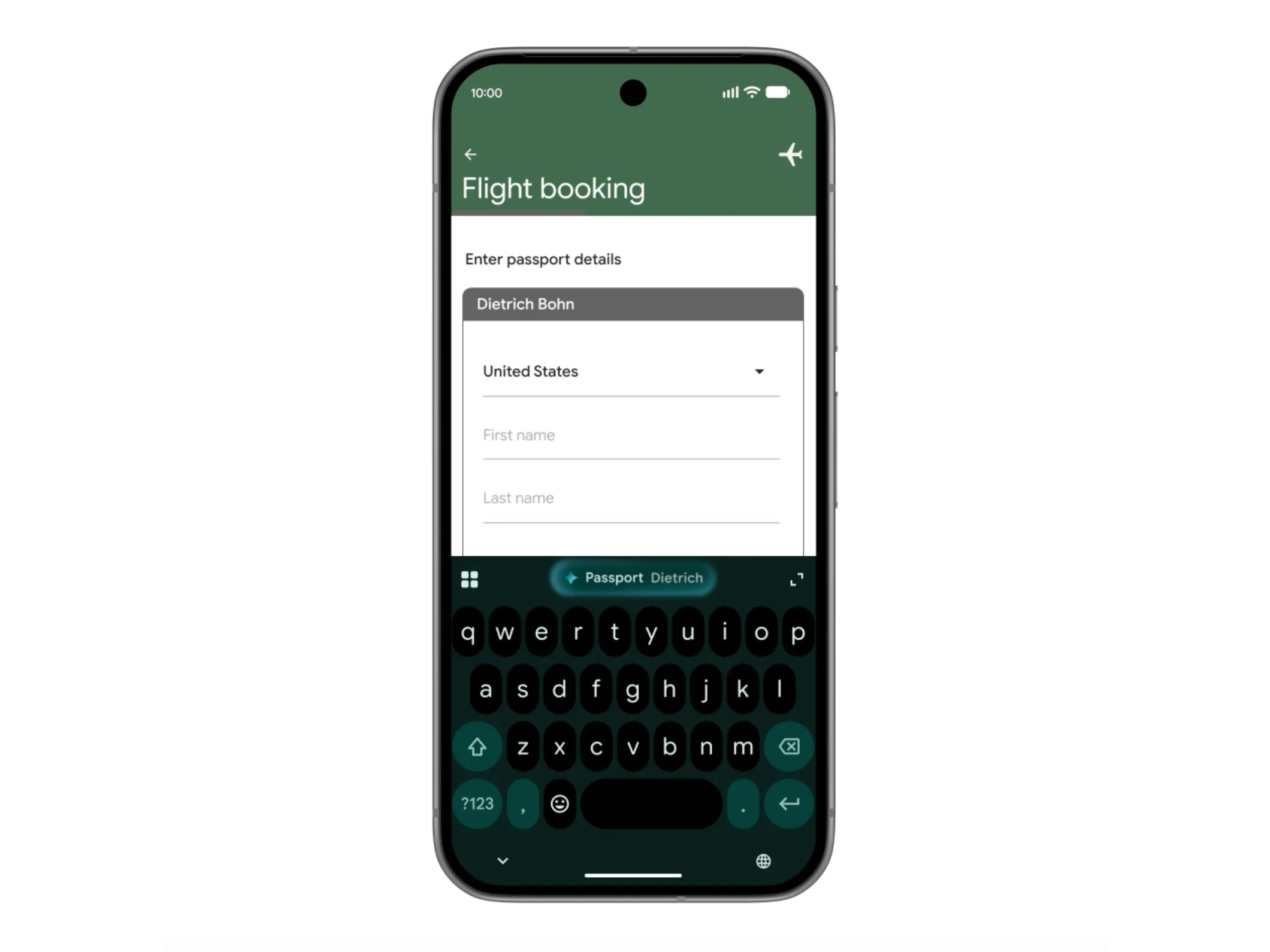
在系统层的另一个重要入口——自动填表方面,Gemini 也将“有条件地”更深度介入。Google表示,用户可以选择将 Gemini 接入Android自动填充功能,由它协助填写各类表单。 为此,Gemini 会借助其所谓的“个人智能(Personal Intelligence)”接口,在获得授权的情况下,从 Google Photos、Gmail 等个人数据源中检索相关信息,例如自动识别照片中的车牌号并填入表格。 这种做法一方面明显提升了填写效率,另一方面也引发了关于隐私与便利边界的新讨论——到底是“极其贴心”,还是“有点诡异”,留给用户自行判断。
根据Google的规划,Gemini Intelligence 旗下各项功能将在今年内“分批次、按成熟度”陆续上线,首批推送对象仍将是三星 Galaxy 和Google Pixel 等高端Android机型,预计从今夏开始陆续接收更新。