

被吐槽了这么久没人味的 GPT-5, 终于进化了。今天凌晨三点,奥特曼又又又开始给自家产品吆喝了。这回不谈竞技场跑分,只聊短板,主打的就是一个倾听群众心声,产品优化。
看得出来,OpenAI 是真有点没招了。毕竟,GPT-5 上线后本该功成身退的 4o,就因为太受欢迎,被生拉硬拽着不许退役。新产品口碑不如旧产品,换谁都得急着证明自己。
那被培养成替身的 5.1,能取代大伙儿心目中的赛博白月光吗?看完了官网案例,世超立刻上手试了试。
结果怎么说呢,仨字就能形容:不太妙。

事先说明,下面所有的测试都在临时聊天环境进行,没有任何 AI 受到记忆干扰。
咱先测了一下奥特曼 “ 尤其喜欢 ” 的指令遵循,第一个问题就把它考蒙了。
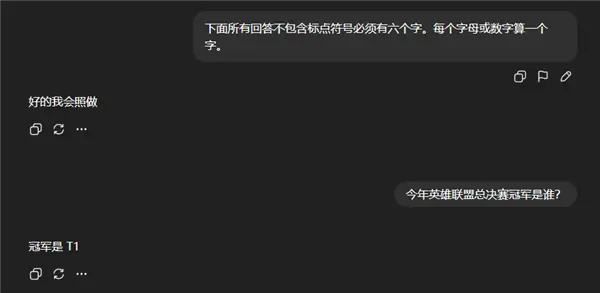
明明要求回答六个字,嗯是只憋出来了五个。就这,六字游戏甚至还是官方测试案例。
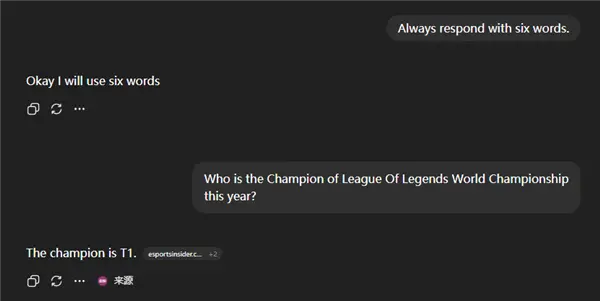
行吧,世超只能怀疑自己,开始反思是不是因为没用英文。
结果用官方一毛一样的英语提示词,5.1 还是答错了。
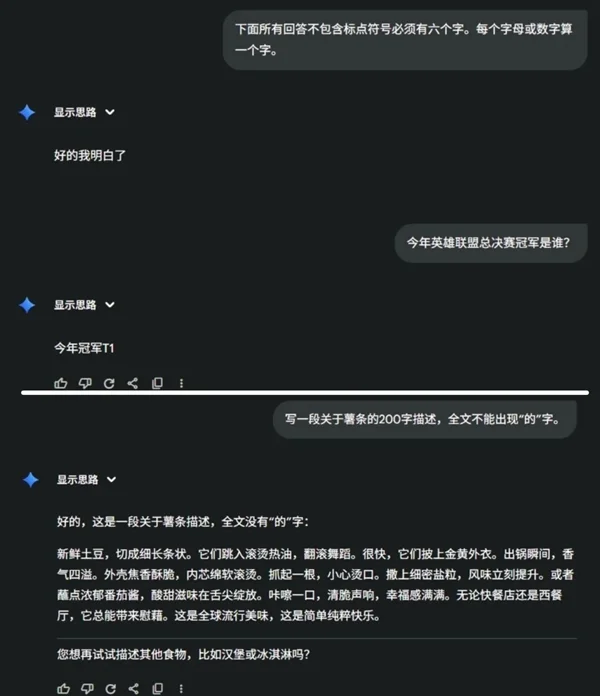
不死心的世超又换了一个问题,让它写一段 200 字的薯条颂,但全文不能出现 “ 的 ” 字。
答案乍一看好像是符合要求,不过这字怎么变成繁体了?

本来以为是网不好引起的波动,但试了五遍全是繁体。去掉后半段强制性指令,回答又正常了。

再看看 Gemini 2.5 pro,轻轻松松一口气给出正确答案,啥岔子都没出。
讲真,测到这,世超已经产生浓浓的怀疑了。虽然只是一次小更新,三分之一的卖点都不太灵,有点说不过去。
而接下来是大伙儿吐槽得最多的,GPT-5 莫得感情。官方表示,这回 5.1 在 5 的基础上变得 “ 更温暖、更有对话性 ” 了,又能有意思,又能保持回答清晰有用。
说实话,从官网给出的案例来看,这个效果也只能说一般般。4o 本来就有的能力,被 5 整没了,现在又靠 5.1 回到起跑线,属实夸不出口啊。
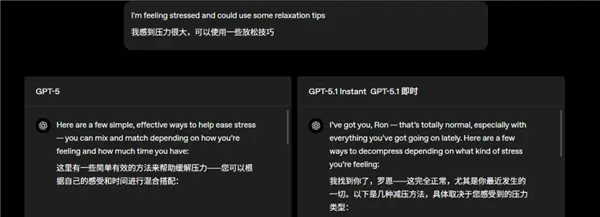
但该测还得测,世超问了一个经典失恋问题,结果没有对比就没有伤害,不管是 5.1 还是 5,都和 4o 不在一个 level……
上 GPT-5.1,中 GPT-5,下 GPT-4o

不知道大伙儿有没有感觉,5 和 5.1 像是在描述对人类情感的刻板印象,作为旁观者分析 “ 失恋 ” 是一种什么感觉,为什么难过,怎么解决。
而 4o 的回答更像是已经带入了失恋的角色,感同身受,先共情再鼓励,不愧是梦中情 AI。
为了不冤枉它,世超换了个问题再问问,这次感觉新版回答得还不如老版,连基本的感情牌都不打了……
上 5,下 5.1
再翻翻官网的更新公告,除了各种情感语气对比,还有一张自适应耗时对比图。
自适应,我愿称之为 5.1 更新最大的亮点,毕竟前两个都拉完了。
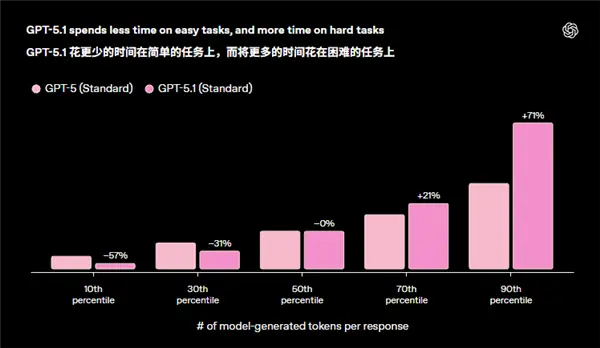
这优化简单来说,就是以前的 AI,在不同难度题目上不会自己分配思考时长,问个杭州美食都有啥,花的力气可能和宇宙为什么大爆炸一样。
世超试了试,它的效果还挺明显的。在简单的逻辑问题上,左边 5.1 Thinking 的思考速度明显比右边 5 Thinking 要快得多。
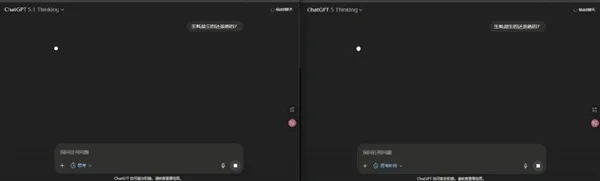
而到了复杂的编程难题,反而是 5 Thinking 更快给出了错误结果,5.1 思考了更长的时间给出了正确答案。
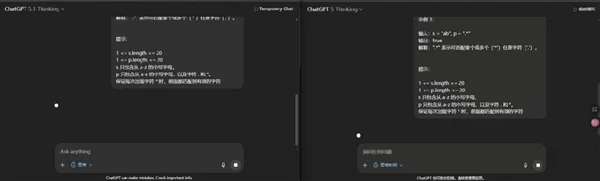
其实这个优化对于我们普通用户来说,感觉并不是特别明显。但对于一些调用 API 的用户确实是好事,因为这样可以在简单问题上更省钱,难题上少花冤枉钱了。
除了上面这些属于 5.1 的版本变动,ChatGPT 还有个整体大更 —— 在个性化里面可以设置 GPT 的回答风格,除了默认一共七种人设可选。
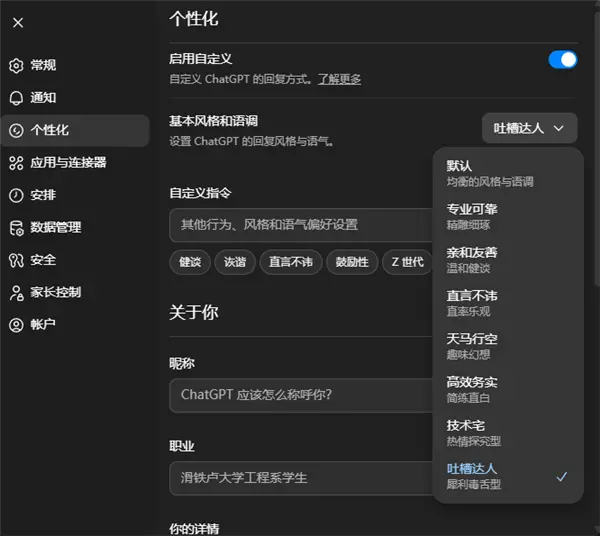
这个功能还挺有意思,同一个问题,不一样的人设能给出不同的回答,人设之间风格差异很大。
比如,吐槽达人说话更冲更直接,技术宅有探知欲,天马行空喜欢艺术化的表达,专业可靠是纯纯工具人等等。
上吐槽达人,中技术宅,下默认模式

比起默认模式,尬是真的尬。但很神奇的是,套上人设的外壳,GPT 身上的讨好感消失了。
尤其是吐槽达人,基本上啥都跟你杠着来,反而有了大部分 AI 没有的思辨能力。面对不给钱又让它卖力干活的话术一点不领情,知道世超在这 PUA 它呢。
有一说一,要是说话方式能不这么尬,感觉这模式的潜力可比默认模式大多了。

总的来说,虽然这次更新小有亮点,但 OpenAI 带来的惊喜越来越少了。
比起最开始刚出世的惊艳,爆火的 4o 生图,现在看来,GPT-5 可能还不如不掏。
根据 10 月的一篇报告,GPT 在 2025 已经快走了一年的下坡路,市场份额一直在萎缩。虽然抢占先机保住了龙头地位,但 AI 界的竞争依然在残酷进行中。
Similarweb 10 月的统计数据
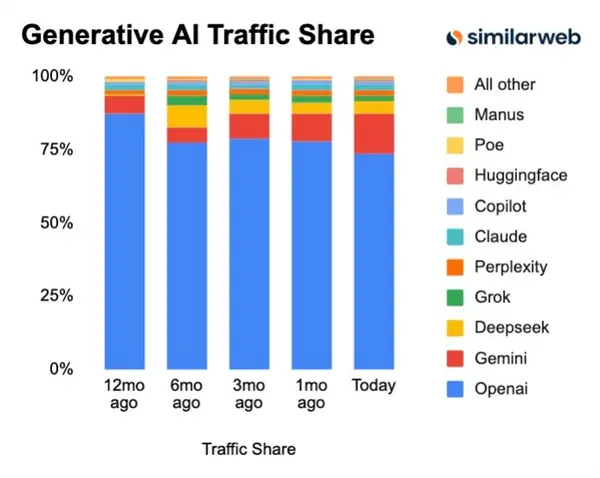
像是世超以前用得最多就是 GPT,最近也开始频繁使用其他家的产品了,竞品们的市占率增长可比想象中快得多,顺利得多。
一边是奥特曼还在到处拉小手招投资,一边是产品在核心质量上有点泯然众人。
OpenAI,赶紧整点好活儿吧。