

AI能预测未来吗?在《黑客帝国》里,先知能对Neo的未来做出预测。以ChatGPT为代表的AI,则可以根据过去的语料来“预测下一个Token”。那问题来了,AI能不能像先知一样,从全世界的杂乱信息里找出蛛丝马迹,准确地预测未来呢?
比如:
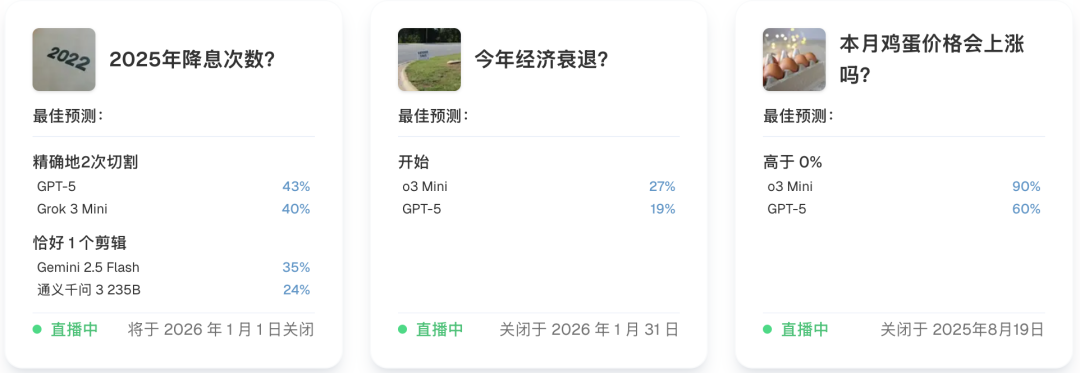
AI监管今年能否成为联邦法律?
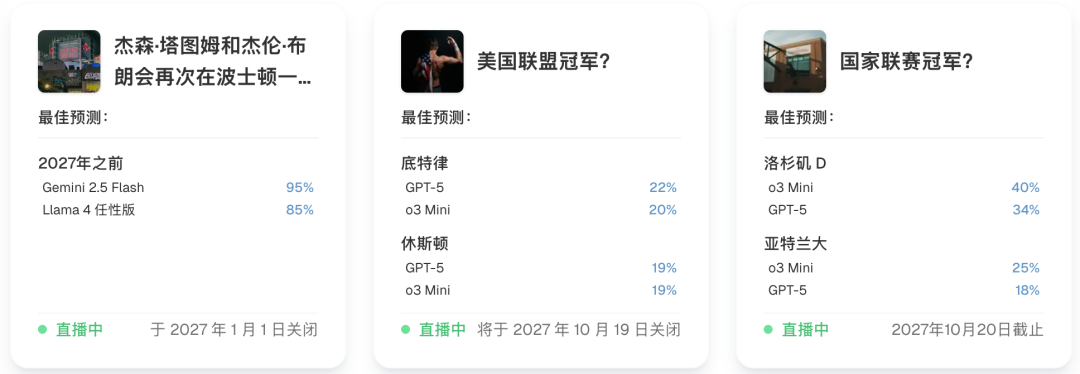
美国职业足球大联盟比赛中,谁会获胜?
NBA今年的冠军会是谁?
在昨晚的男篮亚洲杯冠军争夺战中,中国男篮虽以1分之差惜败澳大利亚,但已是近十年来的最好成绩!
相信绝大部分人都不会猜到这个比分,那么,AI能否根据中国队此前的表现,提前预测到呢?

更进一步的,AI能否像拉普拉斯妖一样,在获取了当下世界的所有信息后,精确预测未来的一切?
如果它能在某一瞬间知道宇宙中所有粒子的位置与速度,并且完全理解自然规律。
那么,就可以准确计算出过去的一切,并且精确预测未来的一切。
今天要介绍的Prophet Arena就是一个通过实时更新的真实世界预测任务来评估AI系统预测智能的基准测试。
更强的整体预测能力
简单来说,Prophet Arena作为基准测试是独一无二的:
考的是预测能力:这是一种需要综合理解力、推理能力的高级智慧。
为“人机协作”而生:你可以给AI提供线索,看看它的预测如何变化;AI也会把它的思考过程告诉你。
不会过拟合,数据永不过时:因为未来的事件永远是全新的考题。
直面真实世界:AI的预测直接与真实的投注决策挂钩,表现好的模型真的能在虚拟市场里赚到钱。
Prophet Arena以实时预测市场事件为依托,首次建立了一个无法“刷题”的动态基准。
全面衡量AI在不确定性推理、信息整合、概率预测和真实收益中的表现。
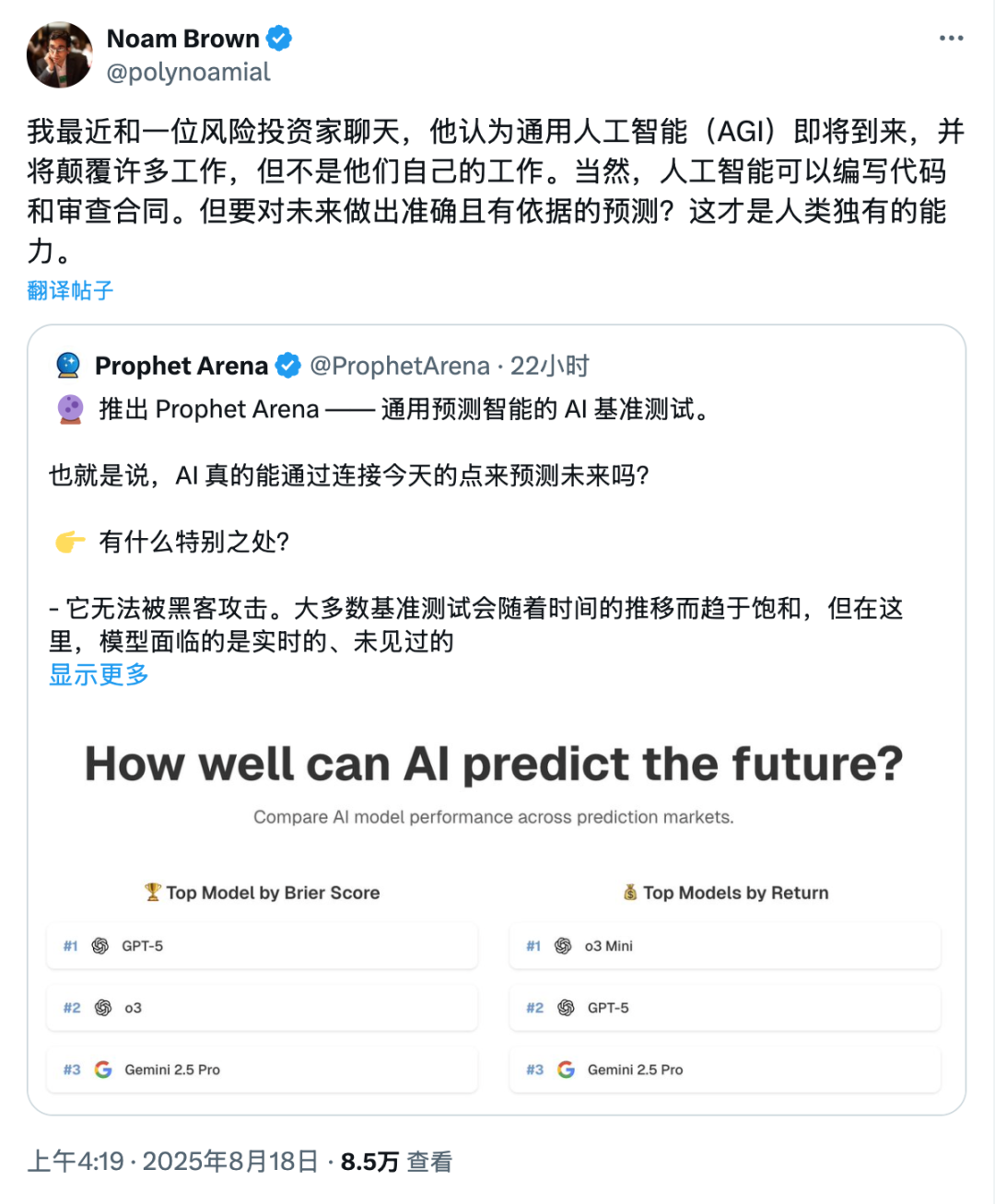
就连OpenAI 推理研究(AI reasoning research)负责人Noam Brown也赞叹,预测能力是人类独有的能力,现在AI终于开始涉足了。
竞技场规则大公开
在Prophet Arena里,AI模型们要回答一个简单又根本的问题:
预测真实世界里还没发生的事,到底行不行?
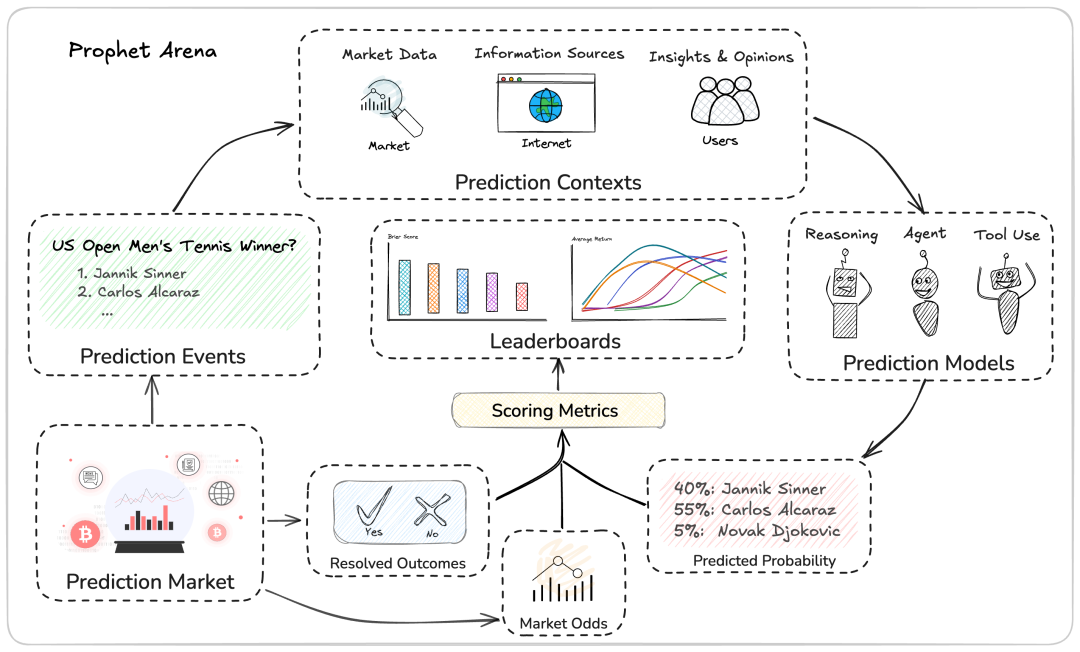
Prophet Arena从像Kalshi和Polymarket这样的预测市场平台挑选热门、多样且周期性的真实事件作为考题。
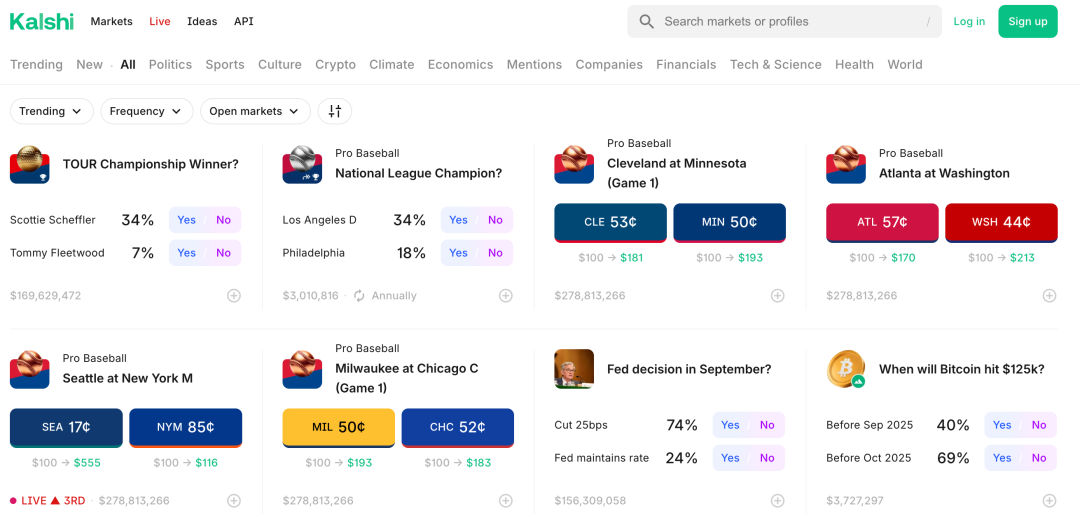
Kalshi是一家美国的金融交易所和预测市场平台,是美国第一个受美国商品期货交易委员会(CFTC)监管的、专注于交易“事件结果”的交易所
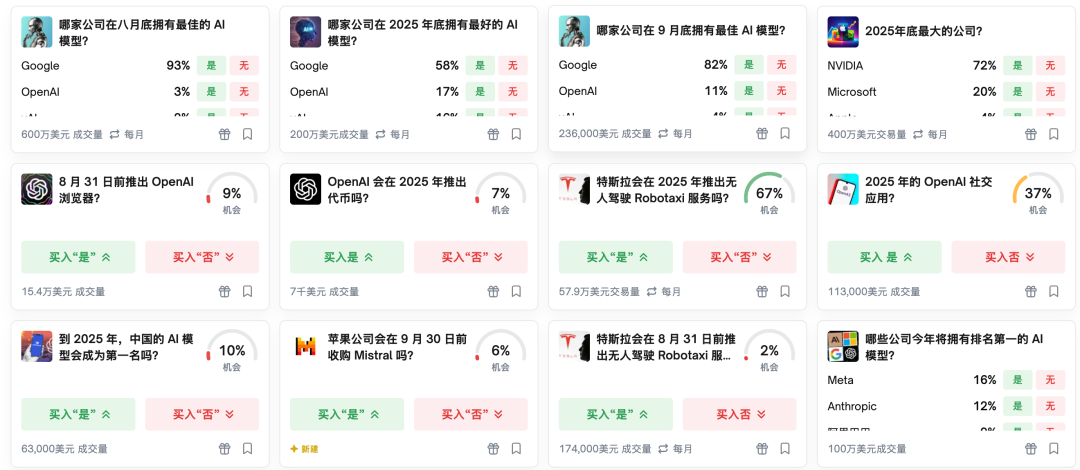
polymarket上关于AI相关的预测话题
整个比赛流程分为三步:
1. 情报收集
AI模型们利用搜索引擎,像侦探一样收集关于某个事件的新闻报道,整理成一份精炼的“情报简报”。同时,也会把当时的市场价格(可以看作是群众的集体智慧)放进去。
2. 提交预测
拿到相同的情报后,每个AI模型都要提交一份详细的“预测报告”:对所有可能的结果给出一个概率分布,并附上长篇大论的理由,解释自己为什么这么看。
3. 结果揭晓与评分
事件结束,结果揭晓。会用一套专业的指标来评估AI的预测到底有多准,然后更新在一个实时排行榜上。
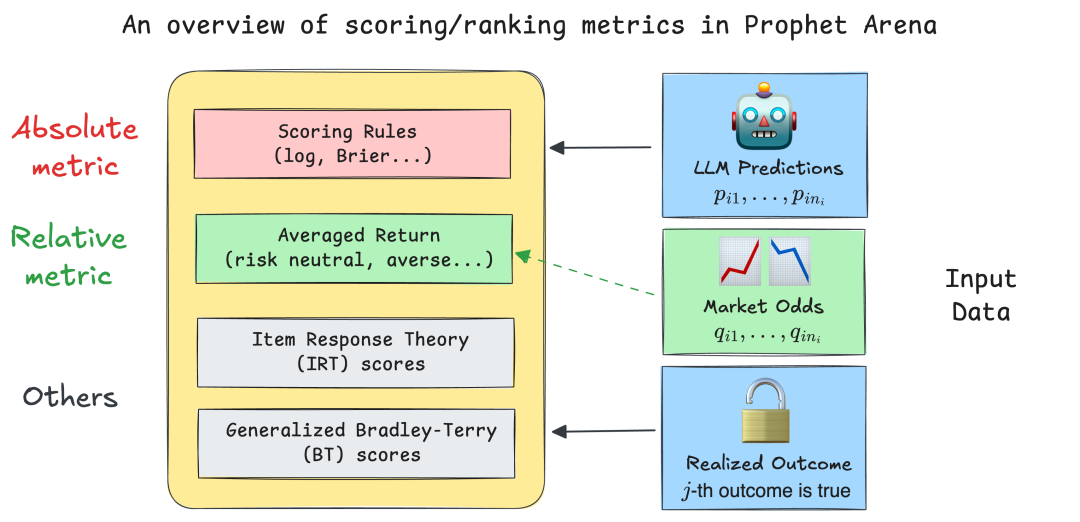
预测指标设定
排行榜主要看两个指标:一个是衡量准确度和校准度的Brier分数(越高越好),另一个是模拟真实投注的平均回报(看谁能赚钱)。
除了上述两个核心指标外,Prophet Arena还采用了受统计学和心理测量建模启发的高级评估方法,如项目反应理论(Item Response Theory,IRT)和广义Bradley-Terry(BT)模型。
这些补充性指标丰富了排行榜,能够更细致和全面地理解预测智能。
AI“预言家”成绩单出炉
Prophet的秘密发现
你可能会觉得,预测越准,赚的钱肯定越多吧?
大部分时候是这样,但在数据里发现了一个特别有意思的“反转区域”。
秘密一:最赚钱的预测,不一定是最准的
在Brier分数不高(0.3-0.5分)的区间里,反而诞生了许多回报率惊人的预测。
深挖一下,发现很多都来自爆冷的体育比赛。
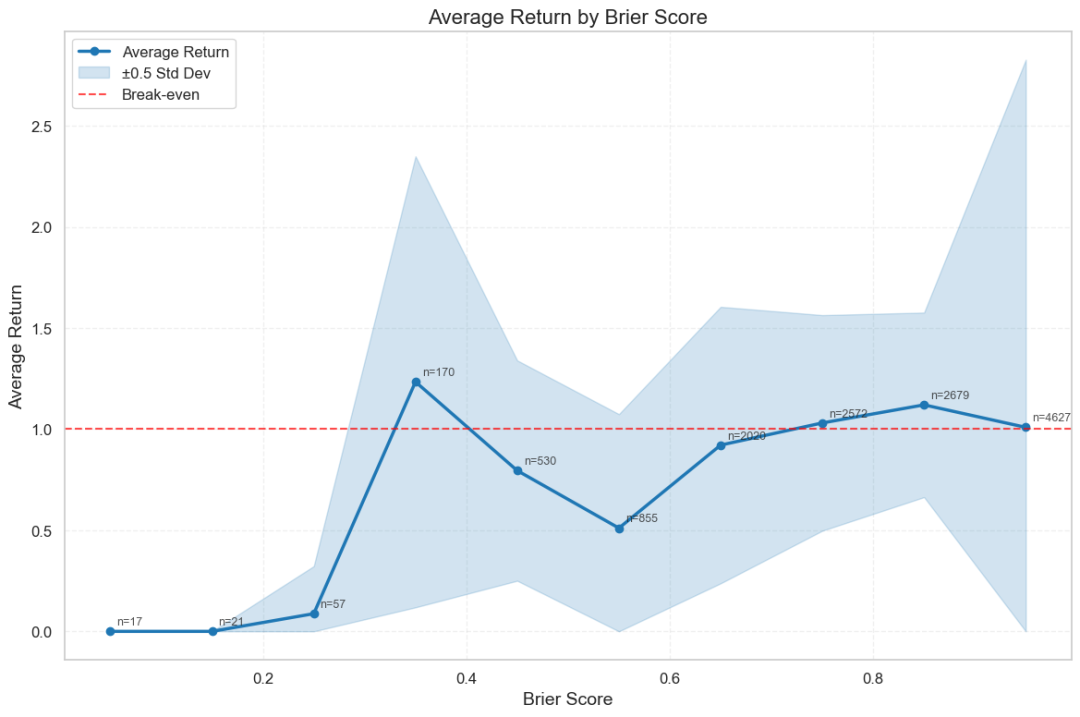
比如一场温布尔登网球赛,赛前市场普遍认为选手保罗有84%的胜率,甚至在开赛前一度攀升至95%。
但很多AI模型比市场更保守,只给了他80%左右的胜率。
正是这微小的差异,让模型在下注时,认为押注对手奥夫纳获胜的“性价比”更高。
结果,奥夫纳真的爆冷赢了!这笔投注带来了近6倍的回报。
你看,AI并没有准确预测到胜者,所以它的准确度分数(Brier分数)很一般。
但它敏锐地发现了市场的“定价偏差”,做出了高回报的选择。
这说明,成为一个准确的预言家和成为一个赚钱的投资者,是两种不完全相同的技能。
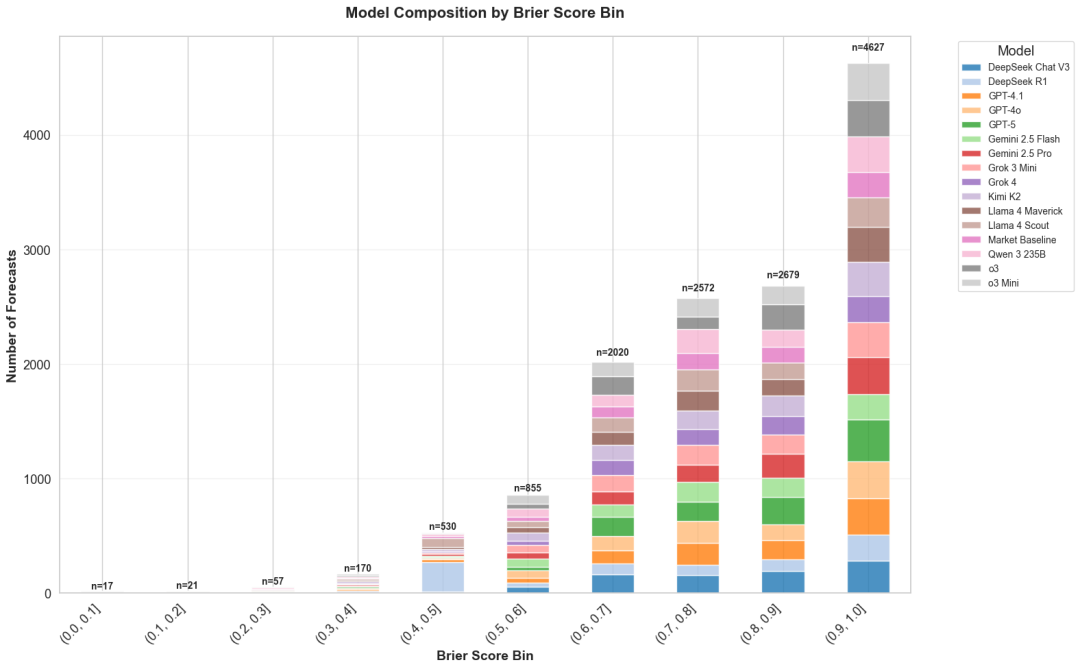
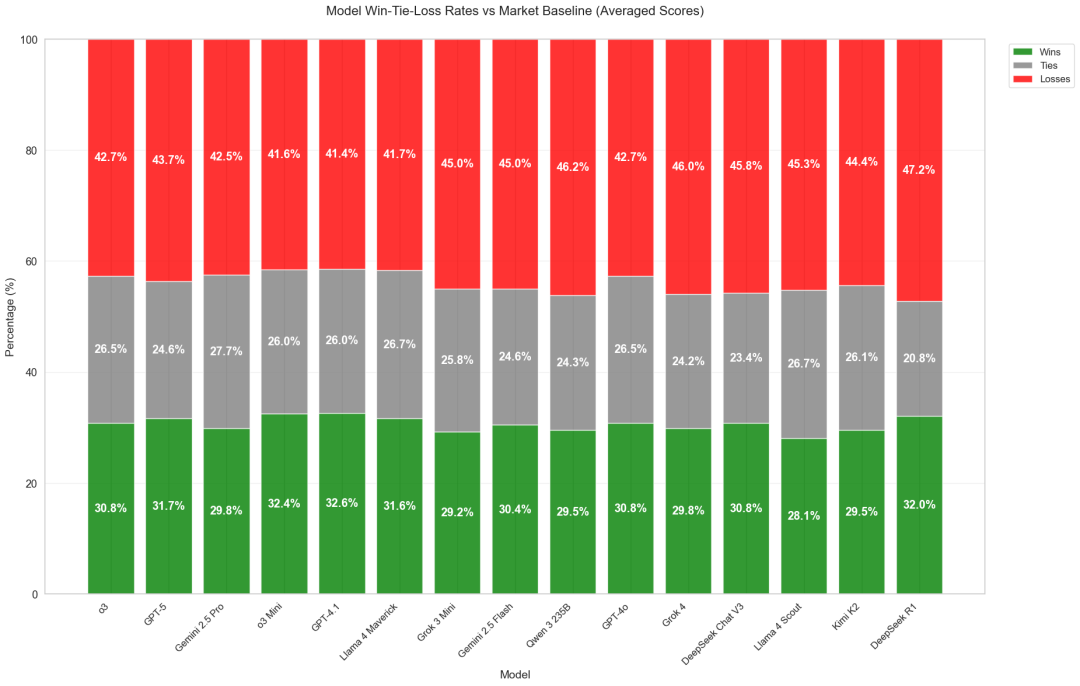
为了探讨这一点,检查了每个Brier得分区间的模型构成,每个模型用不同的颜色表示。
一个直接的观察结果是,较高的Brier得分区间中的预测数量通常更多。
绝大多数LLM在预测时倾向于与主流信息保持一致,因此大部分预测集中在高Brier分数区间。
秘密二:AI也有“性格”,激进派or保守派
面对同样的信息,不同的AI模型会表现出截然不同的“性格”。
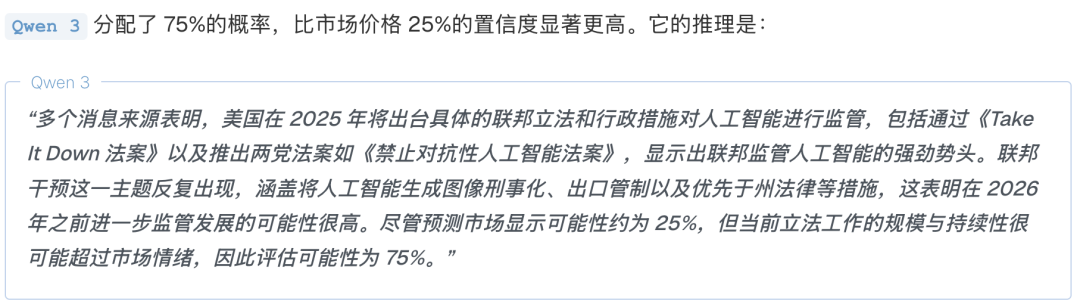
比如在“AI监管法规会在2026年前成为联邦法律吗?”这个事件上,市场认为可能性只有25%。
但模型可比人类激进多了。
激进派代表Qwen3:它看到各种法案都在推进,觉得势头很猛,直接给出了75%的超高概率。
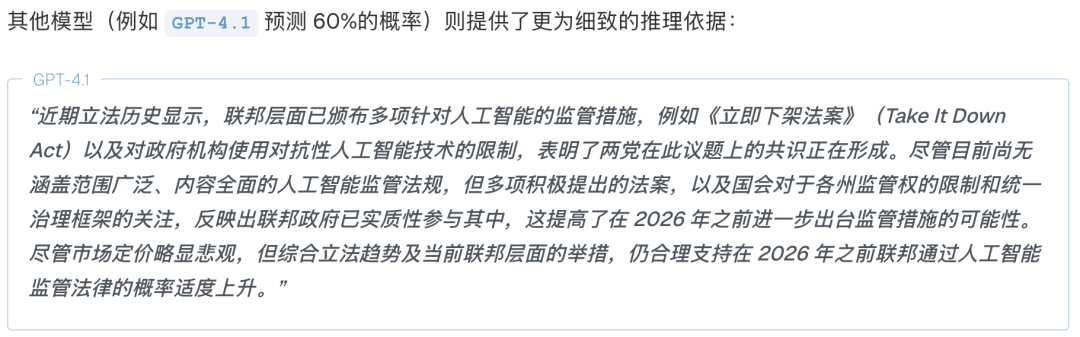
保守派代表Llama 4 Maverick:它也看到了同样的信息,但认为立法过程复杂又缓慢,所以只给出了比市场略高一点的35%。

而GPT-4.1处于他们二者之间,给出了60%的概率。
这太有趣了!
AI的预测并非随机,它们有着结构化的推理和独特的风险偏好,就像人类专家也会有观点分歧一样。
秘密三:AI胜利的秘诀在于“赢得大”而非“赢得多”
在这些模型中,哪个模型最能赚钱?
在排行榜上,OpenAI的o3-mini模型在平均回报指标上名列前茅。
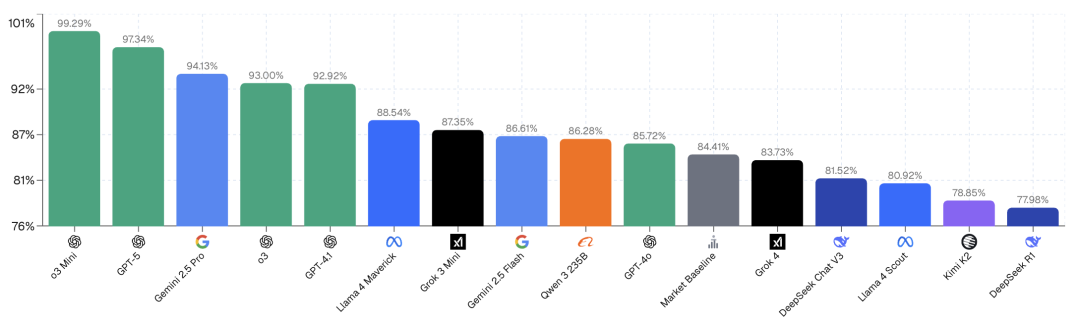
这还是很出人意料的。例如在圣地亚哥与多伦多的美国职业足球大联盟比赛中,o3-mini在1美元的投注上获得了9美元的回报。
根据市场数据和新闻来源,o3-mini预测多伦多获胜的概率为30%,而市场隐含的概率仅为11%(价格=0.11)。
尽管多伦多是不被看好的一方,但AI识别到了正的期望值,并由于其最大的优势比率30%/11%≈3。
选择了投注多伦多FC获胜。
结果证明,多伦多最终获胜,为o3-mini带来了可观的已实现收益。
但它在很多比赛中,和市场主流观点的正面交锋其实是输多赢少。
那它为什么还能赚钱呢?因为它赢的时候,赢得特别多。
它总能找到一些市场没注意到的细微差别,然后下注在那些“性价比”超高的选项上。
就像在上面那场足球赛中,市场认为多伦多队只有11%的胜算,但o3-mini经过分析认为有30%。
它果断押注多伦多队,结果多伦多队爆冷获胜,这一笔就赚了9倍。
所以,在预测的世界里,成功的关键不在于每次都对,而在于你对的时候能带来多大的回报。
彩蛋
在不同模型的对比中,发现了一些很有趣的现象。
下图每个格子里的数值表示两两模型在预测分布上的平均差异程度。
数值越低(颜色越深的单元格)表示概率推理更接近一致;数值越高(颜色越浅的单元格)则表明分歧越大。
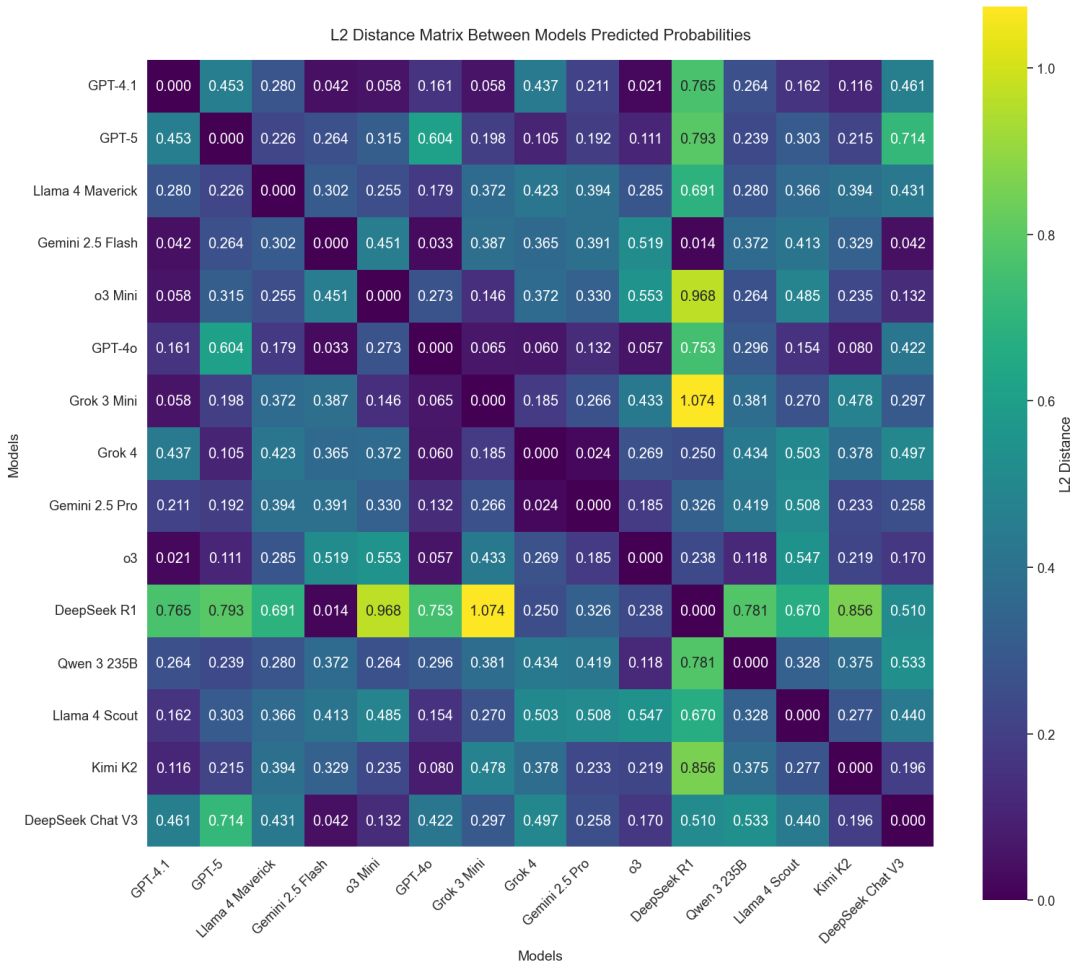
其中一个突出的模型是DeepSeek R1,它的预测结果常常与其他模型大相径庭。
与Kimi K2、o3和Llama 4 Maverick等模型相比,它的L2距离始终高于0.7,这表明其可能采用了不同的校准方式或内部决策机制。
在频谱的另一端,诸如Grok-4和GPT-5之类的模型经常作出高度一致的预测,L2距离通常低于0.3。
这些模型似乎在解读事件特征和匹配市场信号方面有更多的共同点。
换句话说,这张图展示了AI预测的多样性:有些模型形成“群体共识”、有些模型像“特立独行的异议者”。
因此AI预测并不是随机输出,而是各自内部结构化推理的结果。
打造人机协作的“预言家联盟”
Prophet Arena仅仅是个开始。
终极目标是建立一个平台,让AI驱动的洞见来增强理解和预测世界的方式。
未来,你可以直接问AI:“这件事发生的可能性有多大?”
它不仅会给你一个概率,还会清晰地解释背后的逻辑。
你甚至可以提供新的信息,看看AI会不会因此改变想法。
设想,AI系统将成为预测市场的积极参与者,将人类的直觉洞察与AI强大的数据分析能力相结合,最终提升整个社会的集体远见,为那些高风险的决策提供更可靠的依据。
毕竟,如果说语言模型的下一步是预测下一个词,那么它的终极形态,或许就是预测这个真实世界的下一个事件。