

DeepSeek正式发布DeepSeek-V3.2-Exp模型,官方App、网页端、小程序均已同步更新为该版本,同时API大幅度降价。


▲DeepSeek-V3.2-Exp的Hugging Face页面截图
DeepSeek-V3.2-Exp的一大亮点是价格暴降。在新的价格政策下,开发者调用DeepSeek API的成本将降低50%以上。
据悉,DeepSeek-V3.2-Exp API的输入价格由0.5元/百万tokens降低为0.2元/百万tokens(缓存命中),由4元/百万tokens降低为2元/百万tokens(缓存未命中),输出价格由12元/百万tokens降低为3元/百万tokens。

▲DeepSeek-V3.2-Exp的全新价格政策
这得益于新模型服务成本的大幅降低。V3.2-Exp是一个实验性(Experimental)的版本,作为迈向新一代架构的中间步骤,在V3.1-Terminus的基础上引入了一种稀疏注意力机制(DeepSeek Sparse Attention,DSA),针对长文本的训练和推理效率进行了探索性的优化和验证。
据悉,DSA首次实现了细粒度稀疏注意力机制,在几乎不影响模型输出效果的前提下,实现了长文本训练和推理效率的大幅提升。
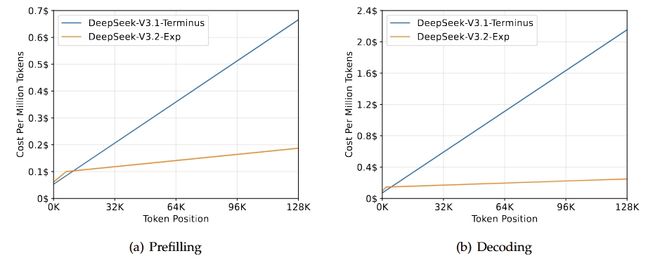
▲DeepSeek-V3.2-Exp相比V3.1-Terminus效率提升
为了严谨地评估引入稀疏注意力带来的影响,DeepSeek特意把DeepSeek-V3.2-Exp的训练设置与V3.1-Terminus进行了严格的对齐。在各领域的公开评测集上,DeepSeek-V3.2-Exp的表现与V3.1-Terminus基本持平。
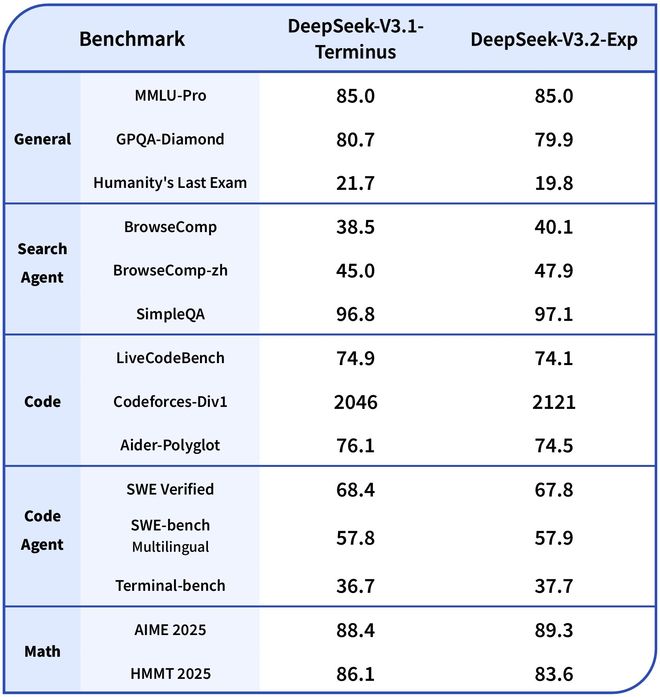
▲DeepSeek-V3.2-Exp与V3.1-Terminus测评表现对比
DeepSeek-V3.2-Exp一经发布,就在外网社交平台X等炸开了锅。有网友对“成本降低50%”表示赞叹,也有网友对DeepSeek“周更”的节奏表示满意,还有更多网友催更DeepSeek新一代模型R2及V4,并期待DeepSeek打败OpenAI。
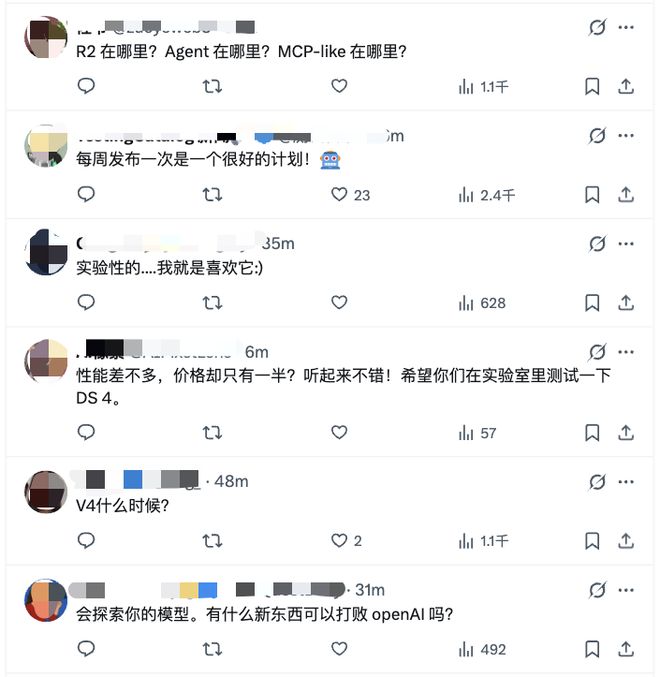
▲社交平台X网友热议DeepSeek-V3.2-Exp
国产AI芯片公司纷纷第一时间宣布完成DeepSeek-V3.2-Exp的适配。
华为发文宣布,昇腾已快速基于vLLM/SGLang等推理框架完成适配部署,实现DeepSeek-V3.2-Exp 0day支持,并面向开发者开源所有推理代码和算子实现。其在128K长序列下能够保持TTFT低于2秒、TPOT低于30毫秒的推理生成速度。

▲华为计算官方公众号发文
寒武纪也发文宣布,其已同步实现对深度求索公司最新模型DeepSeek-V3.2-Exp的0day适配,并开源大模型推理引擎vLLM-MLU源代码。DeepSeek-V3.2-Exp叠加寒武纪的极致计算效率,可大幅降低长序列场景下的训推成本。

▲寒武纪开发者公众号发文
作为一个实验性的版本,DeepSeek-V3.2-Exp虽然已经在公开评测集上得到了有效性验证,但仍然需要在用户的真实使用场景中进行范围更广、规模更大的测试,以排除在某些场景下效果欠佳的可能。
为方便用户进行对比测试,DeepSeek-V3.1-Terminus临时保留了额外API访问接口,保留到北京时间2025年10月15日23:59。
用户只需修改base_url=”https://api.deepseek.com/v3.1_terminus_expires_on_20251015″ 即可访问V3.1-Terminus,调用价格与 V3.2-Exp相同。
DeepSeek-V3.2-Exp模型现已在Hugging Face与魔搭开源。
HuggingFace地址:
https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp
ModelScope地址:
https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2-Exp
论文地址:
https://github.com/deepseek-ai/DeepSeek-V3.2-Exp/blob/main/DeepSeek_V3_2.pdf
结语:DeepSeek再降大模型落地门槛,国产芯片加速适配
DeepSeek的模型迭代速度正在加快。就在9月22日晚间,其刚刚发布了DeepSeek-V3.1-Terminus,优化了编程、搜索智能体等表现。仅仅一周后,DeepSeek-V3.2-Exp随之发布,带来了大幅降低的成本体验。
这预示着DeepSeek的下一代模型很快就要到来了,此前已有外媒报道称,DeepSeek今年年底即将推出Agent模型。值得一提的是,我们看到DeepSeek不仅上线阿里魔搭社区,并立马适配华为昇腾、寒武纪等国产AI芯片,或许意味着其快速迭代及落地应用与国产AI芯片联系更加紧密。