

看起来10月又是一个大月,DeepSeek用v3.2开场,Anthropic,Google,OpenAI都有大动作刚刚,Anthropic发布了其最新前沿模型——Claude Sonnet 4.5。

官方称,这是目前全球最强的代码模型、最强的复杂智能体构建模型、以及最擅长使用计算机的模型,并且在推理和数学能力上取得了显著进步
伴随新模型发布的,还有一系列产品全家桶的升级,Anthropic还首次开放了构建Claude Code的同款工具,最后还发布了一个比较科幻的东西叫Imagine with Claude,可以实时动态生成软件,不过目前还是研究预览
Claude Sonnet 4.5现已全面可用,通过API调用claude-sonnet-4-5即可。价格与上一代Sonnet 4保持不变,为每百万token输入3美元/输出15美元
新模型性能有多强?
Anthropic表示,Claude Sonnet 4.5在衡量真实世界软件编码能力的SWE-bench Verified评估中达到了业界顶尖(SOTA)水平。在实际测试中,该模型能在复杂的多步骤任务上保持超过30小时的专注
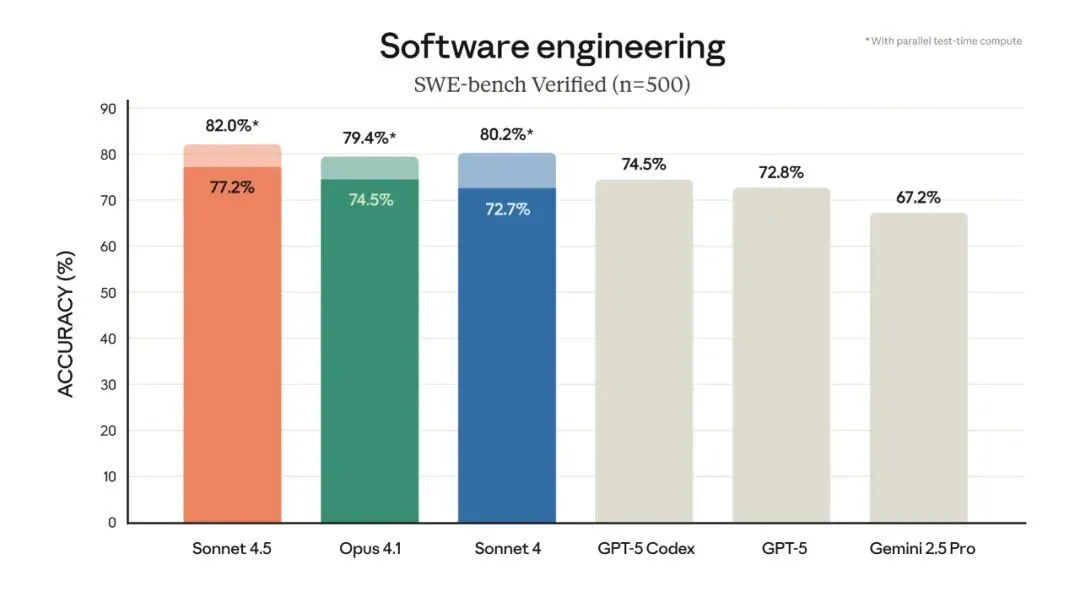
在计算机使用能力方面,Sonnet 4.5也实现了巨大飞跃。在测试AI模型真实世界计算机任务的OSWorld基准上,Sonnet 4.5以61.4%的得分领先。就在四个月前,Sonnet 4还以42.2%的成绩保持领先
此外,该模型在一系列广泛的评估中也展示了更强的能力,包括推理和数学:
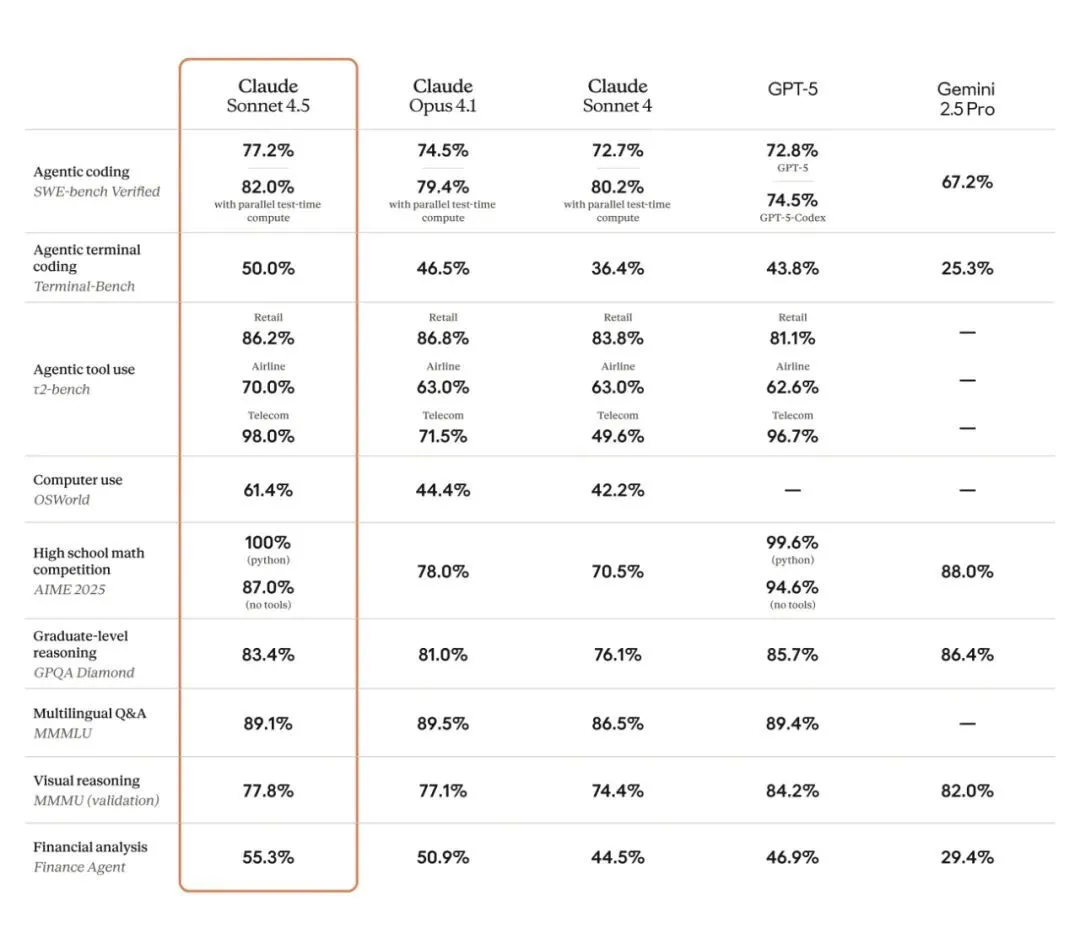
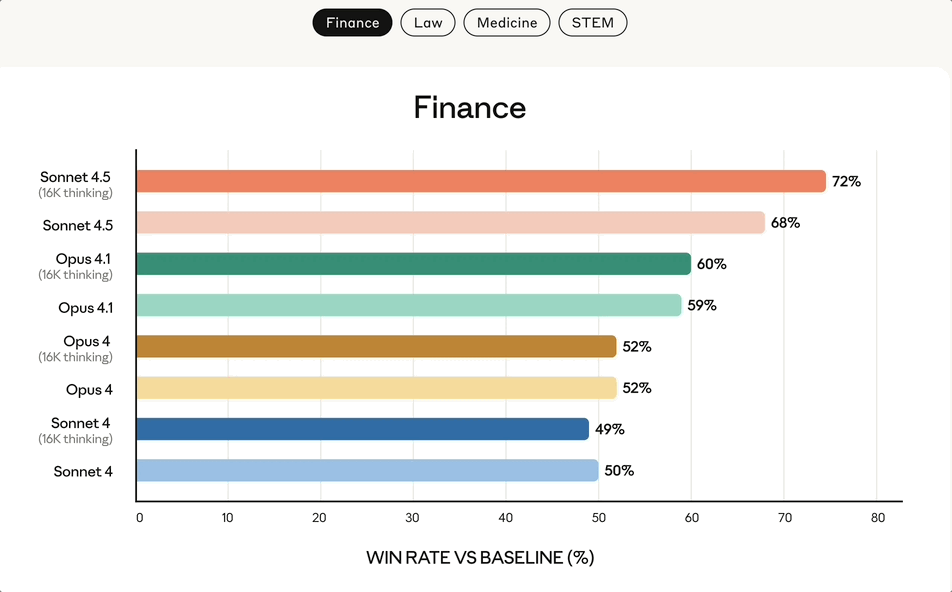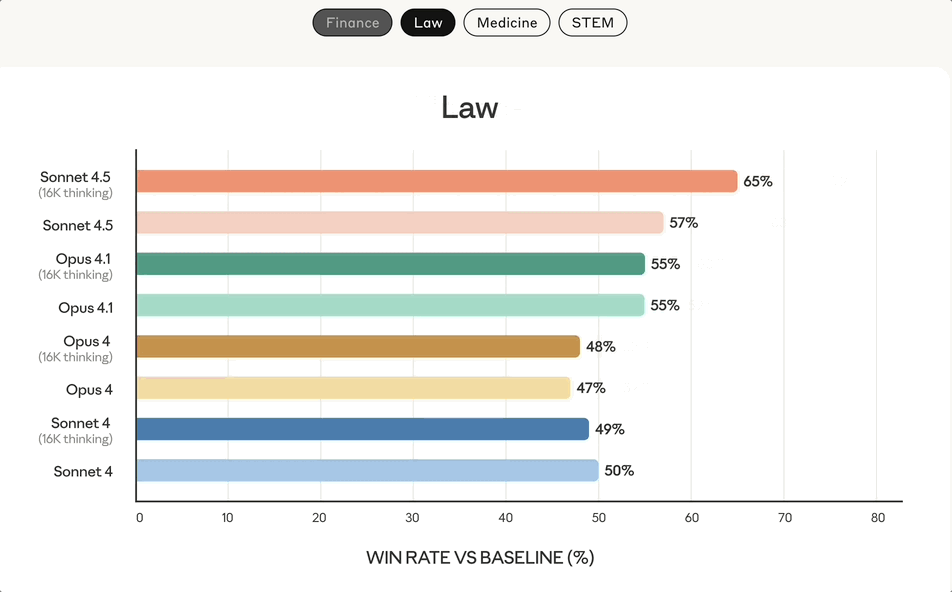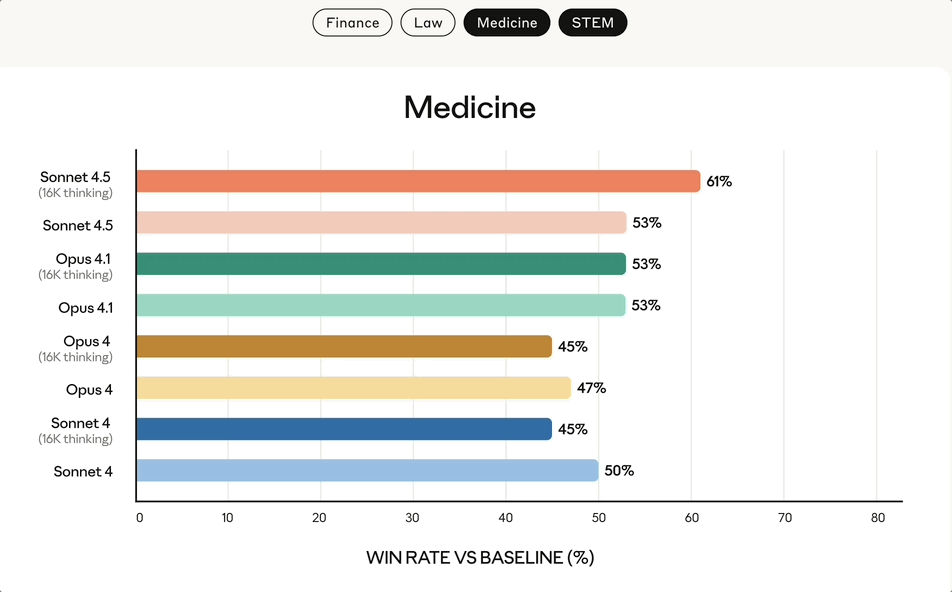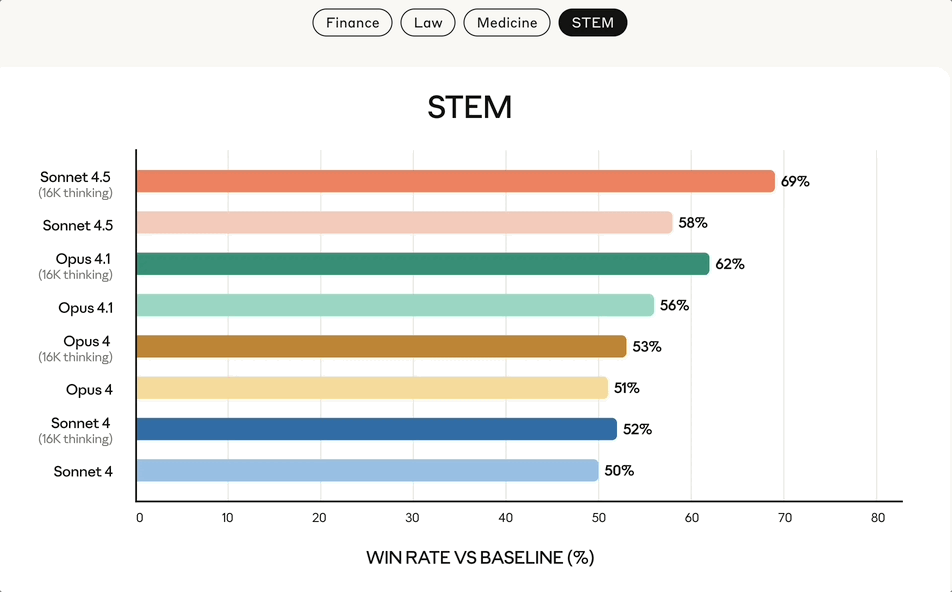
来自金融、法律、医学和STEM领域的专家发现,与包括Opus 4.1在内的旧模型相比,Sonnet 4.5在特定领域的知识和推理能力上表现出了显著的提升
产品全家桶重大升级
Claude Code发布 v2.0 了,升级了 UI 界面,推出了全新的VS Code扩展插件。此外,还有一个实用的新功能:检查点(checkpoints)。通过它,你可以快速撤销Claude刚刚做出的修改,只需轻松按下Esc+Esc快捷键,或者输入指令/rewind即可实现
Claude API增加了新的上下文编辑功能和记忆工具,使智能体能够运行更长时间并处理更复杂的任务。
Claude App中,代码执行和文件创建(电子表格、幻灯片和文档)功能被直接整合到对话中
Claude for Chrome扩展已向所有上个月加入等待名单的Max用户开放
首次开放Claude Agent SDK
Anthropic此次还开放了他们用于构建Claude Code的基石——Claude Agent SDK
官方表示,他们解决了构建AI智能体过程中的多个难题:智能体如何在长时间任务中管理记忆、如何平衡自主性与用户控制的权限系统、以及如何协调多个子智能体以实现共同目标
现在,这套为Anthropic前沿产品提供动力的基础设施正式向所有开发者开放,可用于构建自己的智能体
史上最对齐模型
Anthropic称,Claude Sonnet 4.5是其迄今为止最对齐的前沿模型
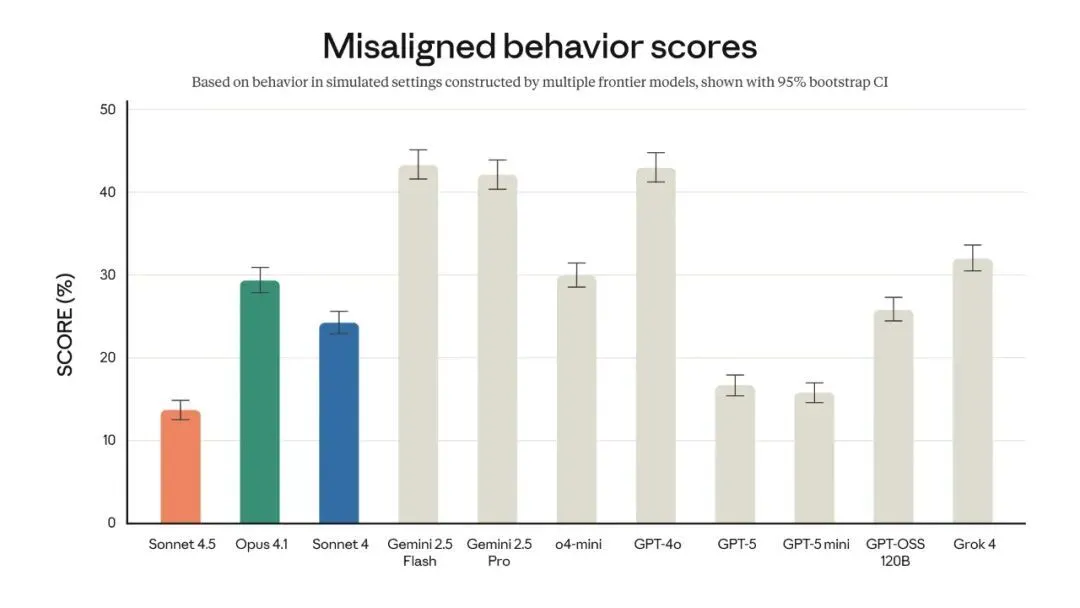
通过提升模型能力和进行广泛的安全训练,模型的行为得到了显著改善,减少了逢迎、欺骗、权力寻求和鼓励妄想等不良行为。针对智能体和计算机使用能力,模型在抵御提示注入攻击方面也取得了长足进步
Claude Sonnet 4.5在AI安全等级3(ASL-3)的保护下发布。这些保护措施包括旨在检测潜在危险输入和输出的分类器,特别是与化学、生物、放射性和核(CBRN)武器相关的内容
如果分类器意外标记了正常内容,用户可以方便地切换到CBRN风险较低的Sonnet 4模型继续对话。Anthropic表示,自最初引入分类器以来,他们已将误报率降低了十倍
one more thing
与Sonnet 4.5一同发布的还有一个名为“Imagine with Claude”的限时研究预览
在这个实验中,Claude能够实时动态地生成软件,没有任何预定功能或预写代码。用户可以看到Claude根据交互请求进行实时创建和调整
该功能向Max订阅用户开放,为期五天
上手小测试
我用之前测试新模型前端能力的提示词测了一下,并且至少进行了5次抽卡,没有一次成功,感觉Claude Sonnet 4.5代码能力提升貌似不大,提示词如下:
模拟,一个由弹力球组成的正方体漂浮在半空中,从正方体最下一层慢慢塌方,注意是,一层一层塌方,小球落在桌子上弹起来,直到静止,模拟整个塌方过程,整个过程符合物理规律,效果要酷炫,整个环境要尽量逼近真实,在单个HTML中实现
实现效果:一次掉落了两层后,小球就不往下掉落了,核心的逻辑没有实现
官方测试方法说明SWE-bench Verified: 所有Claude结果均使用一个包含bash和文件编辑两个工具的简单框架报告。在完整的500个问题的SWE-bench Verified数据集上,通过10次试验平均,无测试时计算,200K思考预算,得分为77.2%
OSWorld: 所有分数均使用官方OSWorld-Verified框架报告,最大步数为100,4次运行取平均值
MMMLU: 所有分数均为在14种非英语语言上进行5次运行的平均值,并使用了扩展思考(最高128K)。
其他模型的得分均引用自OpenAI和Google发布的官方文章或排行榜