

文心大模型4.0,半年时间又提升了52.5%,在智能体、代码、多模型上也有了新进展!像人一样思考的智能体,达到了一定程度的白盒;智能代码助手Comate,让开发者们动动嘴就能开发应用了。
文心大模型,又有新进展了!就在昨天,Create 2024百度AI开发者大会成功举办,又公布了一波智能体、代码、多模型等方面的新进展。去年3月16日,文心一言发布,此后不断迭代。基于更大的算力、更多的数据和更强的算法,依托飞桨平台,文心已经从3.0、3.5,进化到了4.0版本。

AI智能体,像人一样思考
毫无疑问,智能体是业内一致被看好的方向。
对此,百度CTO王海峰也表示,智能体会带来更多的应用爆发。
而如今的百度智能体,已经学会像人一样思考了!
在基础模型上,它进一步进行了思考增强训练,包括思考过程的有监督精调、行为决策的偏好学习、结果反思的增强学习,进而得到思考模型。
于是,它学会了像人一样阅读说明书、学习工具试用,甚至还能调用工具完成任务。

为了详细说明这个过程,我们可以参考一下《思考,快与慢》这本书中的理论。
人的认知系统,可以划分为2个部分:系统1反应很快,但容易出错。系统2反应慢,但更理性,更准确。

在强大的基础大模型之上,百度的研发团队进一步研制了系统2,包括理解、规划、反思和进化。
这样,智能体的思考过程在一定程度上就白盒化了,于是机器可以像人一样思考和行动,自主完成复杂任务,持续学习,实现自主进化。

让我们来具体感受一下,百度智能体的思考过程。
在文心大模型4.0工具版上,我们可以这样提问——
“我要到大湾区出差一周。想了解一下天气变化,好决定带什么衣服。请帮我查一下未来一周北京和深圳的温度,告诉我出差应该带什么衣服,并整理成表格。”
接下来,它就会展示真正的技术了。
首先,它会调用一个“高级联网”工具,来查询当地的天气信息。

然后,它会调用“代码解释器”,来画出一幅温度趋势图。

根据未来一周的天气,它选择了合适的衣物。

最后,它还对结果进行了思考和确认,自动汇总成了一个表格。

整个过程中,它展现出了娴熟的思考和规划能力,有条不紊地把用户需求拆解成多个子任务,一整套过程行云流水。
不仅如此,从万亿级的训练数据中,文心大模型学到的,除了自然语言能力外,还有代码能力。
代码智能体
顾名思义,这个智能体,能够帮我们写代码。
程序员和普通人的之间的壁垒,从此彻底打破,以前程序员才能做的事,现在人人都能做。
代码智能体,是由思考模型和代码解释器两个部分组成。
首先,思考模型会先理解我们的需求,经过一番思考后,把完成任务的指令和相关信息整合成提示,输入给代码解释器。

根据这个提示,代码解释器就把自然语言的用户需求翻译成了代码,随后执行,这样就得到了执行结果,或调试信息。

最后,思考模型还会对代码解释器的结果进行反思确认。
结果正确,就会把结果返回给用户;不正确,就会继续进行自主迭代更新。

在这次大会现场,王海峰更是当场让代码智能体秀了一番技能。
现场的任务是,让它为本次大会嘉宾定制邀请函。

只见一波操作之后,嘉宾的姓名都被填到了邀请函里正确的位置上。
而新生成的邀请函文件,也都是以嘉宾的名字命名的,并打包好一起输出。

动嘴开发,智能代码助手已来
而这位传说中的智能代码助手Comate,听名字就知道它更专业一些。

没错,它的角色是——程序员的AI同侪,也就是说,可以帮专业的程序员更高效地写出更好的代码。
过去,开发者用代码改变了世界。
而现在,自然语言已经成为新的开发语言。也就是说,开发者们未来只需动动嘴,就能完成应用开发。

在模型效果不断提升的基础上,百度进一步构建了上下文增强、私域知识增强、流程无缝集成等能力。
因此,目前百度智能代码助手Comate整体采纳率达到了46%,新增代码中生成的比例已经达到了27%。

代码理解、生成、优化等各种能力,都被Comate无缝集成到研发的各个环节。
比如,仅需告诉Comate“帮我梳理当前项目的架构”,几秒的时间,它就以清晰的条理给出了解答。

它就像助理一样,能帮助程序员提升代码的开发质量和效率。
下面这个示例,就展示Comate是如何帮工程师接手代码的。
可以看到,只通过一条简单的指令,它就快速了解了整个代码的架构,甚至细到每一个模块的具体实现逻辑。
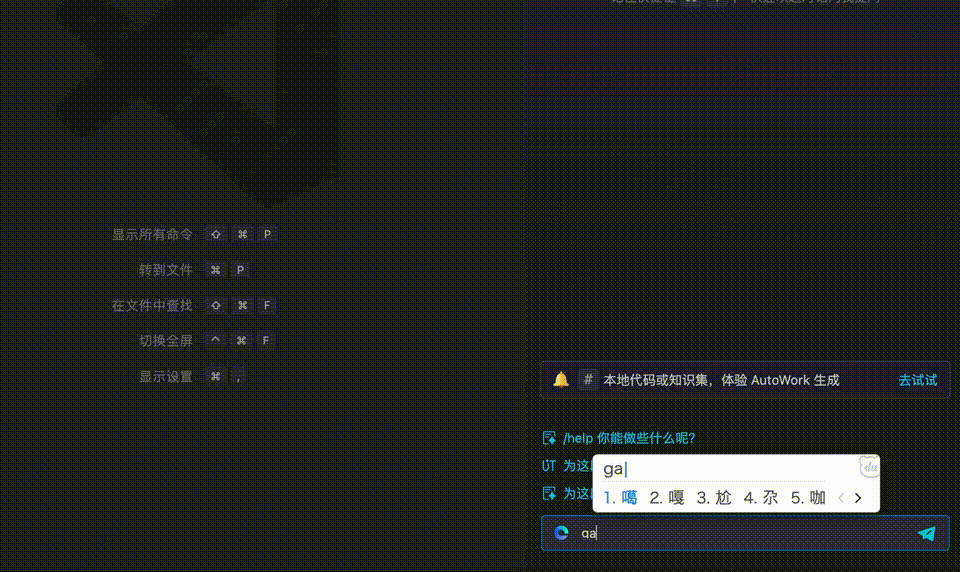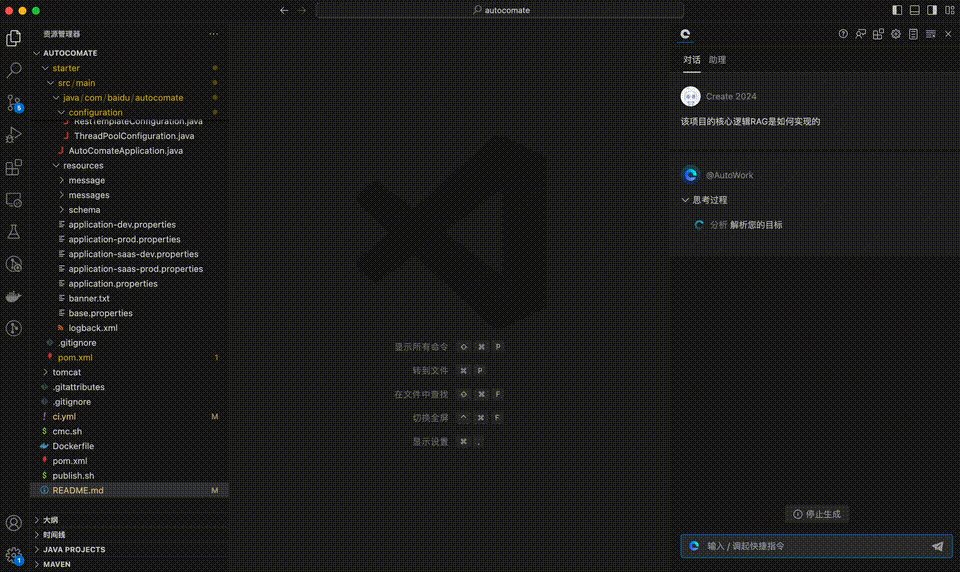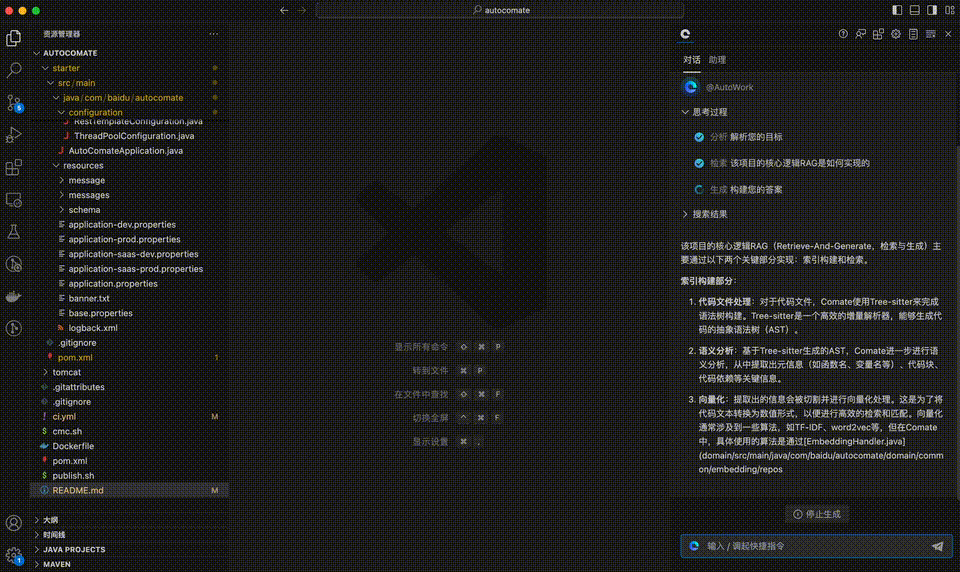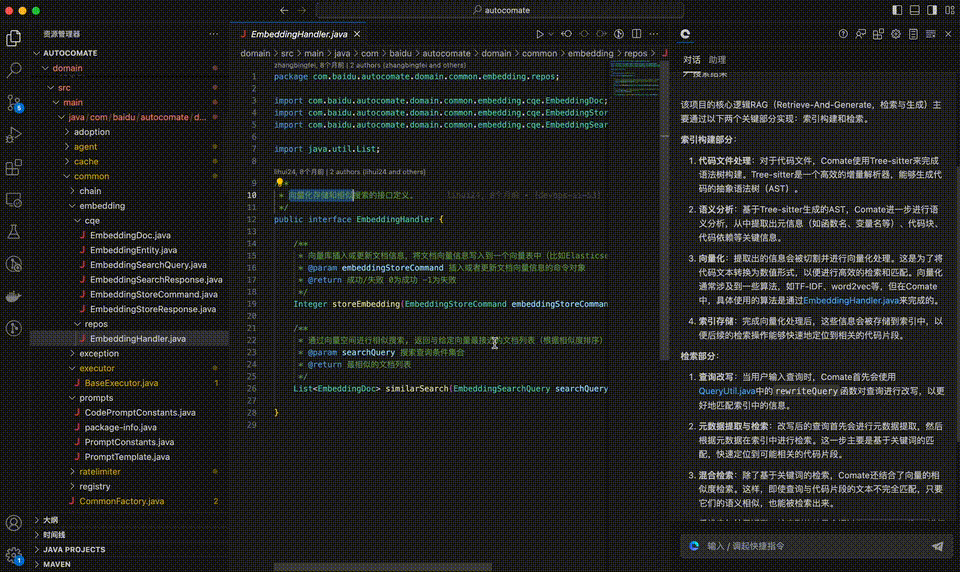
举个例子,当你问到更加细致,具体的内容时——“该项目核心RAG逻辑是如何实现的”,可以迅速得到解答。
更惊喜的是,还有直接跳转查阅的索引链接。
而且,它还可以根据当前的项目代码以及第三方代码,自动生成满足要求的新代码。
如下所示,给出一个外部的参考代码,以及千帆大模型的API,以生成调用Ernie Bot 4.0的代码。
Comate分分钟给出了一个基础代码示例。
大小模型一同训
此外,王海峰在现场还分享了“多模型”技术。
如今,我们为什么需要多模型?
在推进大模型应用落地的过程中,开发者、企业不仅需要关注成本,还需要顾及效果和效率。
因此,在实际应用中,就需要从落地场景出发,去选择最适合自己的模型。

一方面,高效低成本的模型生产亟待解决。
对此,百度研制了大小模型协同的训练机制,可以有效进行知识继承,高效生产高质量小模型。
小模型不仅推理成本低,响应速度快。而且在一些特定场景中,经过微调后的小模型,效果可以媲美大模型。
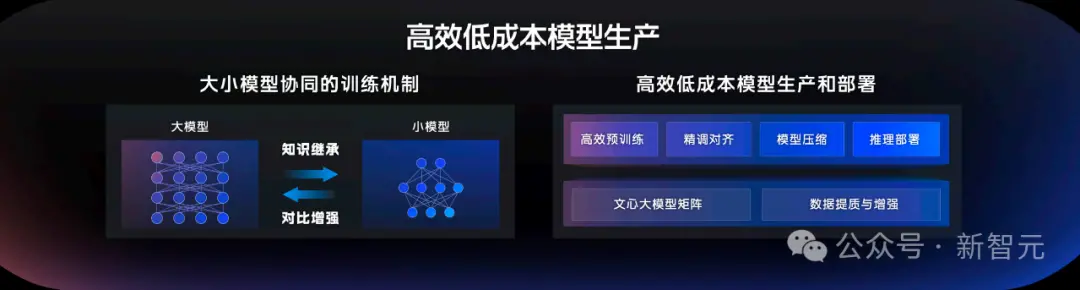
它也可以利用小模型实现对比增强,帮助大模型完成训练。
与此同时,百度还建设了种子模型矩阵,数据提质与增强机制,以及一系列配套工具链,从预训练、精调对齐、模型压缩到推理部署。
这样一来,高效低成本的模型生产机制,可以加速应用,降低部署成本,取得更优的效果。
我们最常见的MoE便是“多模型”技术的典型代表。

可以看到,不论是GPT-4(据猜测),还是开源Grok、Mistral都采用了MoE架构。
它们都在基准测试中,取得了优异的表现。
百度认为,未来大型的AI原生应用基本都是MoE架构。通过大小模型的混用,而非单一模型去解决问题。
因此,针对场景匹配,什么时候调用大模型,什么时候调用小模型,都需要技术考量。
另一方面,是多模型推理。
百度研制了基于反馈学习的端到端多模型推理技术,构建了智能路由模型,进行端到端反馈学习,充分发挥不同模型处理不同任务的能力,达到效果、效率和成本的最佳平衡。

正如Robin会上所言,通过强大的文心4.0裁剪出更小尺寸的模型,要比直接拿开源模型,微调出来的效果要好得多。
这段时间,一张开源模型与闭源模型之间的差距不断拉近的图,在全网疯转。
许多人乐观地认为,开源模型很快突破极限,取得逼近GPT-4,甚至替代闭源模型的能力。
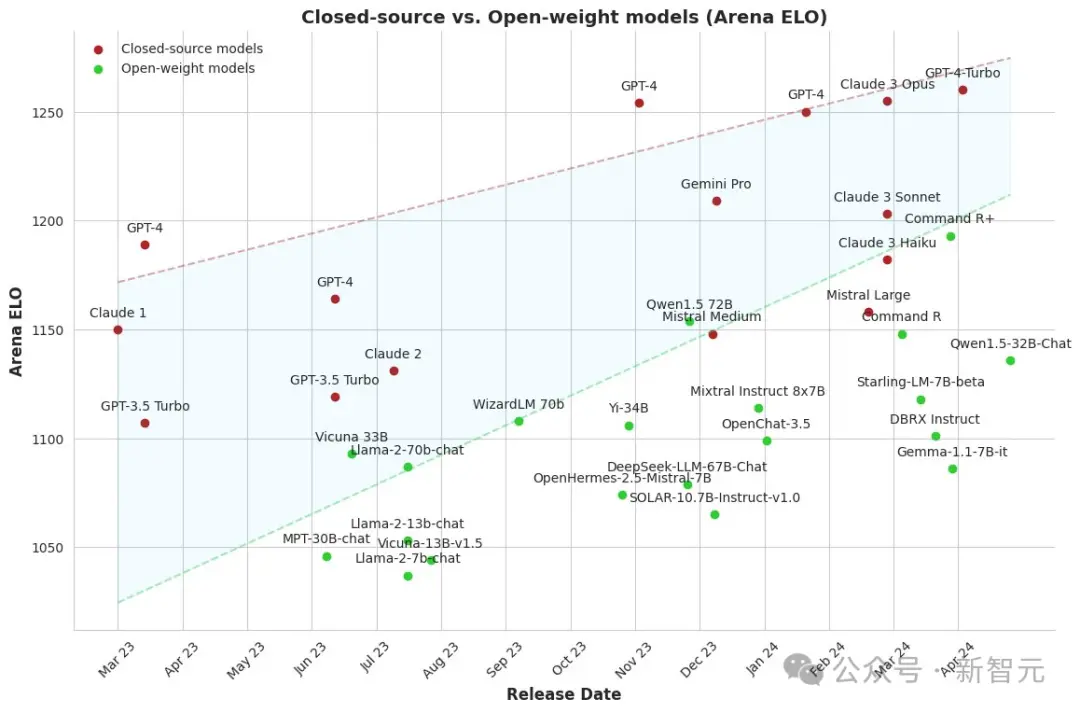
实则不然,开源模型并非拿来即用,而需要更多定制化的微调。
这也是百度发布了ERNIE Speed、Lite、Tiny三个轻量模型的原因。
通过文心大模型4.0,压缩蒸馏出一个基础模型,然后再用专门数据训练。这要比基于开源模型,甚至重训一个模型效果好得多。
文心4.0性能提升52.5%
除了上述这些之外,文心4.0的创新还包括基于模型反馈闭环的数据体系、基于自反馈增强的大模型对齐技术,以及多模态技术等等。

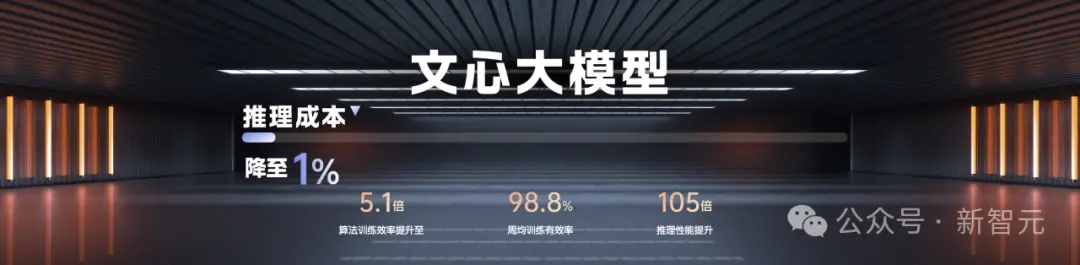
发布后的半年时间,文心4.0的性能又提升了52.5%。

文心大模型之所以能如此快速持续地进化,离不开百度在芯片、框架、模型和应用上的全栈布局,尤其是飞桨深度学习平台和文心的联合优化。文心大模型的周均训练有效率达到98.8%。
相比而言,一年前文心一言发布时,训练效率直接提升到了当时的5.1倍,推理则达到了105倍。
截至目前,飞桨文心生态已经凝聚了1295万开发者,服务了24.4万家企事业单位。基于飞桨和文心,已经有89.5万个模型被创建出来。

如今,文心一言累计的用户规模已达2亿,日均调用量也达到了2亿。
这2亿用户的工作、生活和学习,已经被文心一言改变。
500万AI人才培养计划,提前收官
最后值得一提的是,百度的500万AI人才培养计划,提前收官!
在2020年,百度曾提出5年内要为全社会培养500万AI人才,如今目标已经提前完成。

而王海峰表示,在未来,百度还会继续投身人才培养,让人才的点点星光,汇成璀璨星河。
智能时代,人人都是开发者,人人都是创造者。
参考资料:
https://create.baidu.com/?lng=zh