

Google日前为其 Gemini 聊天机器人推出一项重大升级:用户在提问后,系统不仅可以用文字作答,还能直接生成可交互的 3D 模型和物理模拟场景。这意味着,当用户想“把问题看见”时,Gemini 现在可以通过可旋转、可缩放、带参数控制的三维可视化来进行直观展示。
根据Google介绍,在启用新功能后,Gemini 在生成 3D 模型或模拟时,会同时提供多种交互方式。用户不仅可以拖动旋转模型、放大细节,还可以通过滑块手动调整变量,或输入不同数值,从而实时观察变化结果。对于涉及物理过程或抽象概念的提问,这类交互式可视化有望成为一类新的答案形态。
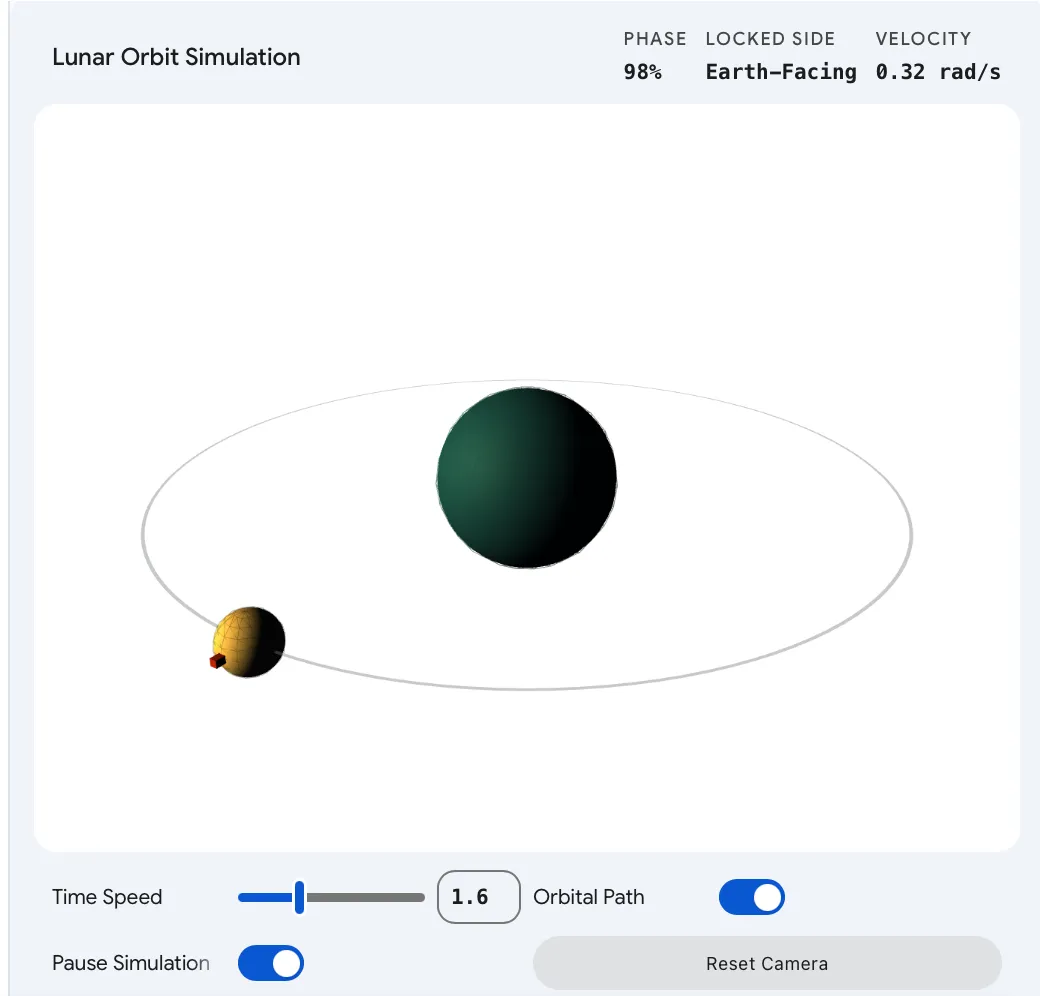
记者在实际体验中,以“生成一个月球绕地球公转的模拟”为例进行测试。Gemini 随即生成了一个可视化的三维场景:用户可以通过滑块调节月球公转速度、通过开关隐藏或显示表示轨道的轨迹线,并使用按钮暂停或继续演示。同时,用户还可以对整套三维模型进行缩放和旋转,从不同视角观察这一运动过程。
在此之前,Gemini 已经支持根据用户提示生成可交互的平面图像,但仍局限于图像层面的交互。此次升级则是将能力扩展到 3D 模型和动态模拟,进一步丰富了 AI 辅助理解和展示复杂概念的手段。这一更新也置身于大模型厂商在“可视化回答”上的竞争之中:不久前,Anthropic 为 Claude 引入了自动生成图表、示意图和其他交互式可视化内容的功能,而 OpenAI 也为 ChatGPT 增加了针对数学与科学概念的可视化工具。
目前,所有 Gemini 应用用户均可通过选择“Pro”模型来体验这一新功能。操作路径为:在应用中将模型切换为 Pro,然后向 Gemini 提出类似“展示一个双摆系统”“帮我可视化多普勒效应”之类的请求。在 Gemini 返回文字说明后,界面下方会出现“Show me the visualization”(展示可视化)按钮,点击后即可生成对应的 3D 模型或模拟场景。